
KI, bitte übernehmen Sie!
Seit 20 Jahren befassen wir uns mit der Idee, dass Software Kundenwünsche verstehen können soll. Unsere ersten Versuche, das Kategorisieren von Kundenanliegen mit Hilfe von künstlicher Intelligenz zu automatisieren, waren ernüchternd. Die Klassifizierungsfähigkeiten der verfügbaren Algorithmen waren ungenügend. Und die benötigten Rechenressourcen zu hoch, um Künstliche Intelligenz (KI) produktiv einzusetzen.
Mit der Weiterentwicklung der Technologie, und der heute zur Verfügung stehenden Rechenpower, war es an der Zeit, diesen Versuch zu wiederholen. Dabei probierten wir aus, ob mit Hilfe von Machine Learning (ML) die Aufgabe der Zuordnung von unstrukturierten Kundentexten zu Kategorien automatisiert werden kann.
In unserem ersten Artikel zu KI und ML haben wir die allgemeine Entwicklung und Einsatzmöglichkeiten dargestellt. In diesem Beitrag beschreiben wir unsere aktuellen Ansätze, wie die Aufgabe „Kategorisieren von Kundenfeedback“ durch den Computer unterstützt, beziehungsweise übernommen werden kann. Bevor wir allerdings auf unsere konkreten Experimente eingehen, möchten wir vorab darstellen, welche Bedeutung das Kategorisieren von Sachverhalten im Kontext „Kundenservice“ hat.
Warum Kategorienbildung?
In jedem Augenblick, in jeder Konfrontation, suchen wir instinktiv nach Wegen, unsere Umwelt zu strukturieren, zu durchschauen, oder zumindest einen Überblick über sie zu gewinnen. Hierbei helfen uns Modelle die Komplexität zu reduzieren. Diese Modelle blenden einen Teil der Wirklichkeit aus und erlauben uns, dass wir uns auf das Wesentliche konzentrieren. Erst mit deren Hilfe sind wir in der Lage, in einer chaotischen Umwelt sinnvolle Entscheidungen zu treffen.
Das fundamentalste Modell, zu dem das menschliche Denken fähig ist, ist dabei die Kategorisierung, oder Kategorienbildung, bei der Objekte und Situationen in Gruppen, Untergruppen oder Begriffsklassen eingeteilt werden. Im Gegensatz zum bloßen Speichern von einzelnen Erfahrungsinhalten, geht dem Kategorisieren ein Denkprozess voraus, der die Ähnlichkeit von Objekten und Situationen untersucht und bewertet. Durch die Kategorisierungsfähigkeit unserer Gehirne erreichen wir eine größere Verhaltensflexibilität bei gleichzeitiger zeitökonomischer Verbesserung des Entscheidungsprozesses.
Was daraus für dein Unternehmen folgt?
Die Denkmodelle, die – bewusst oder unbewusst – in deinem Unternehmen vorherrschen, befähigen oder begrenzen die Fähigkeit, schnell, zuverlässig und wiederholbare Entscheidungen zu treffen. Vor diesem Hintergrund ist das zuverlässige Kategorisieren essentiell, damit du optimale Entscheidungen in deinem Unternehmen triffst. Mit diesem Wissen ergibt sich die herausfordernde Aufgabe, ein Kategoriensystem für dein Unternehmen mit Bedacht und Weitsicht zu entwickeln und anzuwenden.
Die Notwendigkeit eines solchen umfassenden Kategoriensystems ergibt sich insbesondere im Kundenservice. Hier laufen in besonderem Maße unstrukturierte Informationen aus einer Vielzahl von unterschiedlichen Quellen zusammen, die verarbeitet werden müssen. Ein „energiesparendes“ Entscheiden ist nur möglich, wenn das Zuordnen zu Kategorien schnell, einfach und zuverlässig erfolgt.
Anforderungen an ein Kategorisierungssystem
An das im Kundenservice eingesetzte Kategoriensystem ergeben sich damit folgende Anforderungen: Das Kategoriensystem, also das Set an Merkmalen, muss benennbar und minimal hinreichend sein. Es sollte also möglichst wenige Merkmale enthalten. Und dennoch ausreichend umfangreich sein, um alle Sachverhalte, mit denen der Kundenservice konfrontiert wird, zu beschreiben.
Das Kategoriensystem muss sicherstellen, dass die relevanten Handlungsfelder ausreichend repräsentiert sind, um eine hinreichende Informationsgrundlage für Entscheidungen der Geschäftsleitung zu ermöglichen. Am Beispiel einer Airline bedeutet dies konkret, dass der Kundenservice zu den „großen“ Themen auskunftsfähig sein muss:
- Wie viele Fluggäste haben sich bezüglich einer Flugverspätung beschwert?
- Wie viele Gäste haben einen Kofferschaden erlitten?
- Wie viele Anfragen zu Umbuchungen mussten bearbeitet werden?
Darüber hinaus muss es das Kategoriensystem ebenfalls ermöglichen, „kleinere“ Themen angemessen abzubilden. Bei diesen Kategorien geht es weniger darum, die reine Anzahl der betroffenen Kunden und Vorgänge zu ermitteln. Vielmehr ist es notwendig, aus der Menge der Vorgänge ohne großen Aufwand diejenigen zu identifizieren, an denen einzelne Stakeholder ein besonderes Interesse haben.
Gesetzliche Vorschriften führen zu einem Kategoriensystem
Schließlich muss es das Kategoriensystem ebenso ermöglichen, die Vorgänge zu kennzeichnen. Denn Unternehmen sind aufgrund gesetzlicher Vorschriften verpflichtet, gesondert Auskunft zu geben. So fordert die kanadische Luftaufsichtsbehörde, dass Airlines Auskunft über die Anzahl von Beschwerden mit Musikinstrumenten geben. Hintergrund für diese kuriose Anforderung ist vermutlich der Vorfall, bei dem der kanadische Musikers David Carroll die Zerstörung seiner Gitarre während einer Flugreise mit United Airlines selbst mit ansehen musste.
Auch wenn das Kategorisieren primär den Informationsinteressen der Entscheidungsträger im Unternehmen dient, ist ein durchdachtes und gut strukturiertes Kategoriensystem ebenfalls für den Mitarbeiter im Kundenservicehilfreich. Dieser hat die Aufgabe des Kategorisierens von Vorgängen. Beim Reflektieren über die richtige Zuordnung eines Vorgangs zu einer Kategorie, verschafft sich der Mitarbeiter für sich selbst Klarheit und Verständnis über den Vorgang. Dieses „Durchdenken“ erleichtert dem Mitarbeiter die Bearbeitung des Vorgangs und unterstützt das Treffen von angemessenen Entscheidungen. Zusätzlich kann der Mitarbeiter nach Feststellen der Kategorie in der Vorgangsbearbeitung durch targenio entlastet werden. targenio weist den Mitarbeiter auf ähnliche Bearbeitungen hin, zeigt relevante Informationen zur ausgewählten Kategorie an oder schlägt passende Textbausteine für das Beantworten eines Vorgangs vor.
Kategoriensystem im Kundenservice
Der Wert eines Kategoriensystems ergibt sich aus der Nützlichkeit der Informationen, die mit Hilfe der Kategorien codiert werden. Allein hieraus ist sichtbar, dass es keine allgemeingültigen Aussagen für den Aufbau eines Kategoriensystems geben kann. Allerdings haben wir durch die jahrelange Beschäftigung mit dem Thema „Kundenservice“ Erfahrungen gesammelt, wie ein Kategoriensystem aufgebaut und entwickelt werden sollte.
„Ex ante“ oder „Ex post“
Zunächst stellt sich die Frage, was und wann kategorisiert werden soll. Grob vereinfacht finden wir folgenden typischen Ablauf im Kundenservice:
- Input: Der Kunde richtet sein Anliegen an den Kundenservice per E-Mail, über ein Kontaktformular oder per Telefon.
- Processing: Ein Kundenservicemitarbeiter versucht das Anliegen des Kunden zu verstehen, prüft und validiert die Angaben des Kunden, wägt ab und trifft dann eine Entscheidung.
- Output: Anschließend führt der Mitarbeiter die getroffene Entscheidung aus, wählt beispielsweise eine Lösung und informiert den Kunden.
Üblicherweise verbessert sich Art, Qualität und Umfang der Informationen, je weiter eine Bearbeitung voranschreitet. Hat der Mitarbeiter die Bearbeitung abgeschlossen, die Entscheidungen vollzogen, die vom Kunden akzeptiert wurde, sind die bis dahin fluiden Informationen fix. Daraus könnte abgeleitet werden, dass eine Kategorisierung erst nach der Bearbeitung – also ex post – erfolgen sollte.
Tatsächlich ist es aber so, dass am Beginn einer Bearbeitung eine Kategorisierung auf Basis der vom Kunden übermittelten Informationen erfolgt. Das frühe Kategorisieren wird sofort verständlich, wenn man bedenkt, welchen Informationsbeitrag der Kundenservice innerhalb eines Unternehmens leisten kann. Der Kundenservice macht die Stimme des Kunden für das Unternehmen sichtbar.
Zur Verdeutlichung ein anschauliches Beispiel aus der Airline Branche
Ob ein Flugzeug verspätet ist, und den Passagieren Ansprüche auf Ausgleichszahlungen nach Fluggastrechte-Verordnung zustehen, weiß eine Airline meist schon bevor das Flugzeug überhaupt gelandet ist. Diese Informationen ergeben sich aus den operativen Systemen, wie einem Fluginformationssystem. Die Information, wie die Verspätung von den Passagieren wahrgenommen wird, und ihre Reaktionen darauf, besitzt der Kundenservice exklusiv.
Hinzu kommt, dass der Kundenservice mit einer „frühen“ Kategorisierung den Vorgang versachlichen kann. Die Kategorien subtrahieren die Emotionen aus der Kundenäußerung, so dass eine faktenbasierte, rationale Entscheidung möglich wird. Zusätzlich unterstützt die IT die Fallbearbeitung leichter nach dem Zuordnen der Kundenartikulation zu Kategorien.
Ex ante wird oft durchgeführt
Aufgrund dieser Überlegungen erfolgt das Kategorisieren regelmäßig ex ante – also am Anfang der Fallbearbeitung. Gegenstand der Kategorisierung ist dabei die Äußerung des Kunden.
An dieser Stelle soll nicht unerwähnt bleiben, dass häufig auch am Ende der Bearbeitung noch Kategorisierungen vorgenommen werden. Hier halten die Bearbeiter dann fest, ob das Anliegen des Kunden berechtigt war, gelöst werden konnte oder welche Organisationseinheit als Problemverantwortlicher im identifiziert werden konnte. Diese Informationen werden für Qualitätssicherungen oder Root cause analysis benötigt. Das Kategorisieren von Ursachen bleibt einem eigenen Beitrag vorbehalten.
Entwicklung eines Kategoriensystems für den Kundenservice
Nachdem nun feststeht, welche Informationen überhaupt kategorisiert werden sollen, stellt sich die Frage, wie ein sinnvolles und nützliches Kategoriensystem entwickelt werden kann. In der Theorie gibt es induktive und deduktive Methoden zur Kategorienbildung – in der Praxis zeigt sich jedoch, dass keine der Methoden und Ablaufmodelle streng zur Anwendung kommen. Dieses undogmatische Vorgehen ist nachvollziehbar, da jedes Kategoriensystem im Unternehmen das Ergebnis von Verhandlungen ist, bei dem widerstreitende Interessen ausgeglichen werden müssen.
Zum einem erfordern die oben skizzierten Interessen („große“ und „kleine“ Themen, Erfüllung gesetzlicher Anforderung), dass Informationen mit unterschiedlicher Granularität zu Kategorien verdichtet und zusammengefasst werden. Zum anderen bewerten die verschiedenen Stakeholder im Unternehmen die Nützlichkeit der Aggregationen unterschiedlich.
Ein Beispiel: Wenn es für das Bearbeiten eines Kundenanliegens im Kundenservice keinen Unterschied macht, ob der Kunde das Produkt A oder B gekauft hat – weil die Bearbeitung bei beiden Produkten identisch abläuft, so macht es für die Produktmanager von A und B doch einen erheblichen Unterschied, ob „ihr“ Produkt Gegenstand eines Kundenanliegens ist.
Das System muss schnell, einfach und zuverlässig sein
Hinzu kommen weitere Aspekte: Der Kundenservice benötigt ein Kategoriensystem, das schnell, einfach und zuverlässig das Kategorisieren der verschiedenen Kundenanliegen erlaubt. Da die Kategorien aus der Kundenartikulation abgeleitet werden müssen, ist es einfacher ein System zu nutzen, das aus Kundenperspektive heraus aufgebaut ist. Ein anderes Interesse hat unter Umständen das Management, das die Kundenanliegen aus Sicht der Aufbau- oder Ablauforganisation kategorisiert haben möchte.
Ein Kategoriensystem im Kundenservice ist ein Kompromiss: Ein Kategoriensystem, dass die „Order to Cash“ Kette abbildet oder sich entlang einer Customer Journey orientiert, hat sich nach unserer Wahrnehmung bewährt. Ein solches System lässt sich leicht erlernen, was wichtig für den Kundenservice ist. Außerdem findet sich jeder Stakeholder ausreichend repräsentiert.
Daneben hat sich bewährt, die Sicht der Kunden mit der Wertschöpfungskette des Unternehmens zu „kreuzen“. So deckt sich die Kundenperspektive mit der Unternehmenssicht.
Struktur eines Kategoriensystems im Kundenservice
Für targenio haben wir für das Kategorisieren von Kundenanliegen eine Methodik entwickelt, die den oben genannten Aspekten ausreichend Rechnung trägt und sich in der Praxis bewährt hat. Insbesondere gilt das für das Beschwerde- und Reklamationsmanagement. Beim Kategorisieren sehen wir einen mehrstufigen Baum vor, der in vier Entitäten gruppiert ist:
- Art des Kundenanliegens
- Ort des Problemauftritts
- Bezugsbereich
- Kundenartikulation
Jede Entität kann wiederum mehrere Ebenen haben, damit auch umfangreiche Kategoriensysteme abgebildet werden können. „Art des Kundenanliegens“, „Bezugsbereich“ und „Kundenartikulation“ sowie die einzelnen Ebenen sind miteinander verkettet. Von einem Blattelement ausgehend, können alle vorhergehenden Knoten rekursiv ermittelt werden. targenio macht es möglich, eine Kundenartikulation mehreren Kategorien zuzuordnen. Dies vereinfacht die Pflege und Handhabung des Kategoriensystems. Es wird zudem berücksichtigt, dass Kunden in ihrer Nachricht mehrere Themen an den Kundenservice adressieren können.
Vier Ebenen sind in den jeweiligen Entitäten vorhanden
Bei „Art des Kundenanliegens“ wird der Wunsch, das Ersuchen oder der Antrag des Kunden erfasst. Im Beschwerdemanagement sind dies die klassischen Anliegenarten zu finden: „Beschwerde“, „Wiederholungsbeschwerde“ und „Folgebeschwerde“. In anderem Kontext können dies beispielsweise die Anliegen „Anfrage“, „Bestellung“ oder „Lob“ sein.
Beim „Ort des Problemauftritts“ wählt der targenio Anwender die Organisationseinheit aus, die vom Anliegen des Kunden betroffen ist. Diese Entität ist optional, empfiehlt sich aber bei Flächenorganisationen beziehungsweise Dienstleistungsunternehmen, wenn Zuordnungen von Anliegen zu Kunden-Touchpoints relevant sind. Alternativ kann an dieser Stelle ein konkretes Produkt oder eine Dienstleistung angegeben werden.
Der „Bezugsbereich“ repräsentiert die Wertkette des Unternehmens und kennzeichnet die konkrete Aktivität, auf die sich das Kundenanliegen bezieht. Gerade hier empfiehlt sich eine Nachbildung der Tätigkeiten in der Reihenfolge „Order to Cash“, da dies die Verortung im Kundenservice erheblich vereinfacht.
Nach dem „Bezugsbereich“ ist die Kategorisierung mit der Erfassung der „Kundenartikulation“ abgeschlossen. Damit ist das Kondensat des Kundenfeedbacks in konkreten Kategorien dokumentiert.
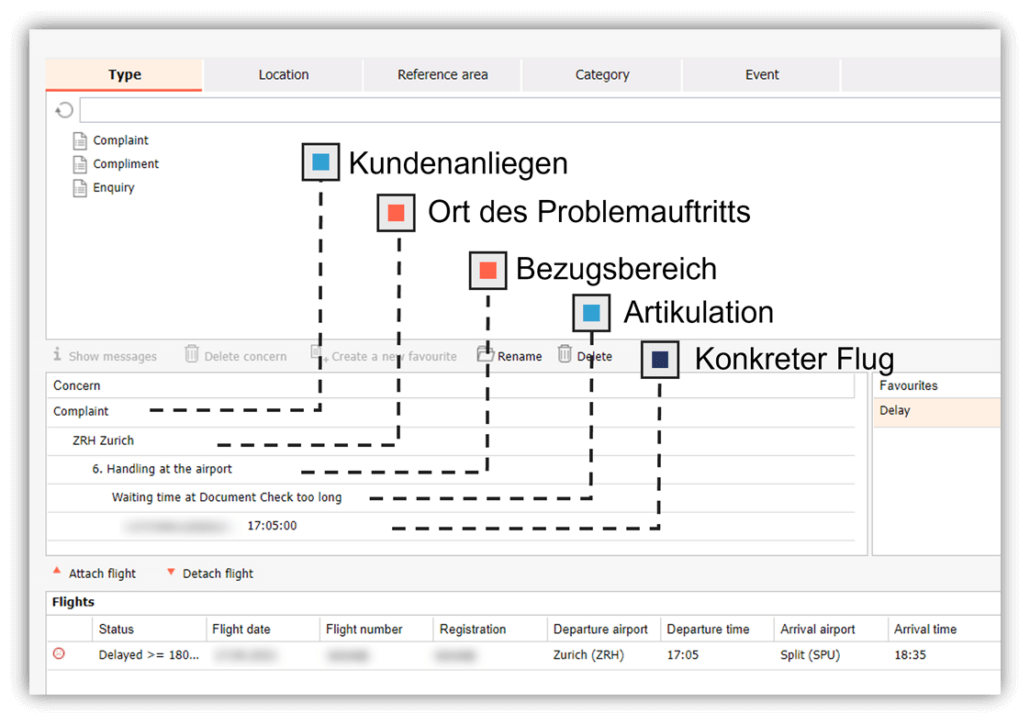
Diese Struktur erlaubt eine schnelle und einfache Zuordnung von Kundenfeedback und berücksichtigt die Auswertungs- und Informationsinteressen der verschiedenen Stakeholder im Unternehmen.
Anwendung des Kategoriensystems
Nachdem das Kategoriensystem entwickelt worden ist, bleibt die herausfordernde Aufgabe, das Kategoriensystem auch in der täglichen Praxis anzuwenden. Selbst wenn Kunden ihr Anliegen unterschiedlich artikulieren, sollen Sachverhalte durch die Mitarbeiter im Kundenservice einheitlich und neutral kategorisiert werden. Hierbei helfen Ankerbeispiele und ausführliche Kodierregeln, die zu einem Kodierleitfaden zusammengefasst werden. Mit Hilfe von Stichprobenauswertungen und qualitativen Analysen muss die Genauigkeit beziehungsweise Verlässlichkeit der Kategorisierung durch die Mitarbeiter im Kundenservice kontinuierlich überwacht werden. Durch Schulungen und Anpassungen des Kategoriensystems sind ständige Nachjustierungen notwendig.
Um den Kundenservice beim Kategorisieren von Kundensachverhalten zu unterstützen, und gleichzeitig weitere Automatisierungspotentiale zu realisieren, beschäftigen wir uns intensiv mit Machine Learning. Die Überlegungen dabei sind, dass die artikulierten Kundenanliegen mit Hilfe von künstlicher Intelligenz analysiert und mittels trainierter Algorithmen dem definierten Kategoriensystem zugeordnet werden.
Forschungsfrage und Versuchsaufbau
Damit wir beim Experimentieren mit Machine Learning fokussiert bleiben, und aussagekräftige Ergebnisse erarbeiten, haben wir zunächst eine konkrete Forschungsfrage formuliert. Diese diente uns während unseres Forschungsprojekts als Leitfaden, und als Gradmesser für Erfolg und Misserfolg.
Folgende Forschungsfrage haben wir formuliert: In welcher Qualität lassen sich Kundenschreiben mithilfe von überwachtem maschinellem Lernen kategorisieren?
Ausgangspunkt unseres Versuchsaufbaus sind Schreiben von Fluggästen, die an den Kundenservice einer unserer Airline-Kunden gerichtet worden sind. Diese Texte geben Kunden über ein Kontaktformular im Internet ein. Zusätzlich wählt der Kunde aus einer Liste aus, welches Anliegen er hat. Zum Beispiel „Flugstornierung“ oder „Überbuchung / Nichtbeförderung“. Den Text und die getroffene Auswahl übernimmt unsere Kundenserviceanwendung targenio und an leitet sie einem zuständigen Sachbearbeiter weiter. Ein Mitarbeiter liest den Sachverhalt und kategorisiert das Anliegen im Kategoriensystem von targenio. Das Kategoriensystem hat in Summe circa 230 Ausprägungen, bestehend aus Anliegenart, zwei Ebenen Bezugsbereich und zwei Ebenen Artikulation.
Die KI lernt, Gesetzmäßigkeiten nachzubilden
Damit liegen also zwei aufeinander bezogene Entitäten vor: Zum einen der unstrukturierte Kundentext, in dem der Kunden sein Anliegen artikuliert hat, zum anderen die durch einen Sachbearbeiter vorgenommene Klassifizierung dieses Textes. Der Sachbearbeiter hat aufgrund seiner Erfahrungen und seines Expertenwissens den unstrukturierten Text in ein strukturiertes System überführt.
Auf Aufgabenstellungen dieser Art wird bei KI-Systemen üblicherweise überwachtes Maschinelles Lernen angewandt. Durch das Trainieren der KI „lernt“ die Maschine, die Gesetzmäßigkeiten nachzubilden und das Expertenwissen aufzubauen. Damit wendet die KI dieses Wissen auch auf unbekannte Texte an und findet eine passende Kategorisierung.
Beim Machine Learning spricht man dabei von Features, hier: Kundentexte, und Labels, in dem Fall der Kategorisierung. Dem Machine Learning Algorithmus werden beim Training Paare aus Features and Labels “gezeigt”. Dadurch erlernt der Algorithmus das zugrunde liegende Mapping. Er lernt also die Kategorien, die in den Texten stecken, zu generalisieren und nutzbar zu machen. Dieses generalisierte Mapping von Feature auf Label ist dann die eigentliche KI. Die Menge an Feature-Label Paaren, die einem ML Algorithmus zum Lernen zur Verfügung gestellt werden, werden Lerndaten genannt. Nach dem Training kann die KI auf neue, ungesehene Features angewandt werden, bei denen sie das passende Label ermittelt.
Lerndaten bereitstellen
Das Bereitstellen von Lerndaten für das ML Modell durchlief mehrere Arbeitsschritte: Zunächst haben wir festgelegt, mit welchen Daten wir den Algorithmus trainieren wollen. Um bereits in den Lerndaten möglichst wenig „Rauschen“ zu haben, wurden Kundentexte, die von Fluggästen in deutscher Sprache verfasst worden sind, extrahiert. Und von Sachbearbeitern lediglich mit einer Kategorie klassifiziert worden sind, sprich monothematische Kundenanliegen.
Nach Prüfung, ob für verschiedene Versuchsreihen eine ausreichend große Anzahl von Daten vorhanden ist, haben wir die Daten in der Datenbank selektiert, anonymisiert und um schützenswerte Kunden- und Mitarbeiterdaten bereinigt. Ebenso haben wir interne Bearbeitungsvermerke gelöscht, um für das Training möglichst unverfälschte Daten zu erhalten. Anschließend exportierten wir die Daten aus der Datenbank im CSV-Format und stellten sie an einem sicheren Speicherort für das Training der ML-Modelle bereit.
Das Kundenfeedback vorverarbeiten
Computer und Algorithmen arbeiten grundsätzlich mit Zahlen. Bevor die Kundenschreiben von der KI verarbeitet werden können, müssen die Texte vor-verarbeitet und in Vektoren umgewandelt werden (“preprocessing). Ein Vektor kann vereinfacht als eine Liste fixer Länge, die Nummern enthält, beschrieben werden. Beispielsweise lassen sich Ortsangaben als zweidimensionaler Vektor, bestehend aus Längen- und Breitengrad in einem Koordinatensystem, definieren. Ein Datenpunkt (ein Sample) fürs Machine Learning ist also ein Vektor, der den Datenpunkt mithilfe numerischer Werte möglichst gut beschreibt.
Für das Umwandeln von Texten in Vektoren gibt es verschiedene Verfahren, die man miteinander kombiniert: Eine Möglichkeit besteht darin, die Häufigkeit jedes Wortes des gesamten Vokabulars im umzuwandelnden Text zu zählen. Zusätzlich lassen sich die Worte noch nach ihrer umgekehrten, relativen Häufigkeit gewichten. Bestimmte und unbestimmte Artikel, Konjunktionen und häufig gebrauchte Präpositionen (sog. Stopwords), die in vielen Texten vorkommen und wenig Relevanz für das Textverständnis haben, gewichet das System dabei schwach, während es seltenerer Begriffe, wie Fachbegriffe, höher gewichtet. Diese Gewichtung erleichtert dem Machine Learning Algorithmus, die wirklich relevanten Charakteristiken des Textes zu erkennen und zu verwenden. Dieses Verfahren nennt man TF-IDF (term frequency – inverse document frequency). Zusätzlich beschränkt das System verbleibende Worte auf ihren Wortstamm (Stemming). Durch das Einschränken des Vokabulars wird das ML-Modell weniger von sogenanntem Noise abgelenkt, und “kann sich auf das wirklich wichtige konzentrieren“.
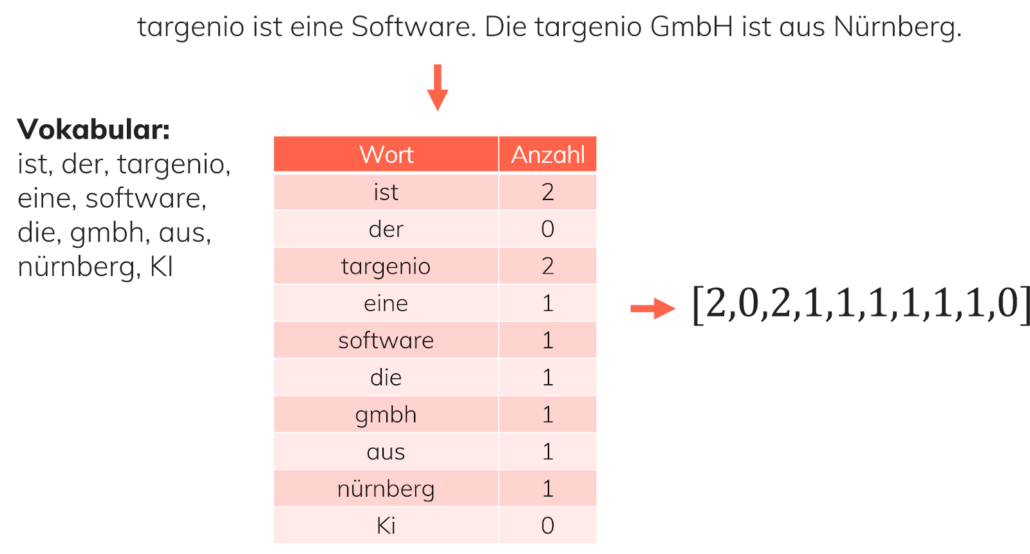
Es kommt nicht nur auf das Zählen an
Diese Verfahren sind robust und liefern regelmäßig brauchbare Ergebnisse. Allerdings geht durch das einfache Zählen der Wörter die Reihenfolge der Wörter, die Grammatik und der Kontext verloren. Für anspruchsvolle Natural Language Processing Aufgaben, wie Übersetzung oder Question-Answering, kommen andere Methoden zur Anwendung. Bei modernen Deep Learning Modellen, die auf der Transformers-Architektur basieren, kommen sogenannte Tokenizer zum Einsatz. Dabei wird jedem möglichen Wort im Vokabular ein fester Ganzzahlwert (das Token) zugeordnet. Diese Modelle verarbeiten den Eingabetext in seiner Ursprungsform, nur dass Wort-Teile durch ihre jeweiligen Tokens ersetzt sind. Auf diese Weise bleibt die Reihenfolge bewahrt und der Sinn erhalten. Modelle, die solche Sätze aus Tokens verarbeiten und verstehen können, müssen ziemlich groß und leistungsfähig sein. Sie benötigen erhebliche Rechenleistungen sowie eine große Mengen an Lern- und Trainingsdaten.
Bei der Wahl des passenden Vektorizers und dem eigentlichen Machine Learning Modell muss zwischen Kosten und Nutzen abgewogen werden. Bei unserem Forschungsvorhaben, dem Mapping von Texten auf Kategorien – eine Aufgabe, die zu den einfacheren NLP-Task gezählt werden kann –, haben wir uns entschieden, das Vektorisieren durch Zählen in Kombination mit einem Nicht-Deep-Learning ML-Algorithmus zu verproben.
Auswahl eines ML Algorithmus
Sind die Daten exportiert, bereinigt und vektorisiert kann man einen geeigneten ML Algorithmus darauf trainieren. Die Auswahl eines geeigneten ML Algorithmus erfordert Erfahrung. Diese sammelt Erfahrungen man durch Ausprobieren. Oder man nutzt hierzu Entscheidungshilfen, mit denen eine Vorauswahl getroffen werden kann. Mit zahlreichen Programmier-Bibliotheken, zum Beispiel diese Erweiterung für scikit-learn, lässt sich der Auswahl-Prozess auch automatisieren.
So nützlich solche automatisierten Auswahlverfahren sind. Es sollte nicht übersehen werden, dass möglicherweise Lernerfahrungen über die Daten und das Verhalten der einzelnen Algorithmen verloren gehen können. Erst beim mühevollen Ausprobieren der verschiedenen Algorithmen sammelt man die Erfahrung, welcher Algorithmus für die Aufgabenstellung und die eigenen Daten besser geeignet ist.
Mehrere ML Modelle werden trainiert, die den Durchschnitt bilden
Für das Kategorisieren von Texten haben sich unter anderem Naive Bayes und Support-Vector-bewährt. Oftmals werden auch sogenannte Ensembles verwendet. Dabei trainiert man mehrere unterschiedliche ML Modelle und bildet den Durchschnitt über deren einzelne Ausgaben, um die Ausgabe des Ensembles zu erhalten. Dadurch werden die Vorhersagen robuster.
Grundsätzlich gilt: keine noch so gute Wahl des Modells kann schlechte Datenqualität kompensieren. Umgekehrt können bei guter Datenqualität mit mehreren verschiedenen ML Algorithmen brauchbare Ergebnisse erzielt werden können. Das zeigen auch die Versuche.
Wir haben uns nach mehreren Iterationen entschieden, unser Forschungsprojekt mit (lineare) Support-Vector-Machine fortzuführen. Diese performt gut und ist gleichzeitig noch relativ effizient. Für das Trainieren der Modelle fiel unsere Wahl auf scikit-learn. Das ist eine open-source Programmierbibliothek für die Programmiersprache Python. Python gilt als der Standard unter ML Entwicklern. Es bietet eine sehr große und gute Palette an Frameworks und Toolkits für Maschinelles Lernen.
Das Training der Support Vector Machine
Support-Vector-Machines erlernen das Kategorisieren (im ML Kontext würde man sagen zu Klassifizieren), indem sie die optimale “Trennung” zwischen Datenpunkten (dargestellt als Vektoren) verschiedener Kategorien in den Trainingsdaten errechnen. Diese Trennung kann nach dem Training benutzt werden, um neue, zuvor ungesehene Datenpunkte einzuordnen.
Wir haben für jede der Kategorienebenen (Art des Anliegens, Bezugsbereich und Artikulation) ein eigenes Modell trainiert, also insgesamt fünf Stück. Damit haben wir bessere Ergebnisse erzielt als mit unserem zunächst gewählten Ansatz, ein Modell für alle Ebenen zu bauen.
Ergebnisse quantitativ auswerten
Um die Qualität der fünf Modelle bewerten zu können, haben wir ausführliche Tests gemacht, wobei das erste Testszenario aus circa 100.000 Datensätzen bestand. Dazu haben wir 30% der Daten beim Trainieren zunächst zurückgehalten. Als das Training mit den übrigen Datensätzen, ca. 70%, beendet war, konnten wir diese zum Testen heranziehen. Durch dieses Vorgehen konnten wir überprüft, ob das ML Modell wirklich die den Trainingsdaten zugrundeliegenden Konzepte erlernt hat. Und es nicht nur die Trainingsdaten auswendig gelernt hat. Dieser Effekt würde als “Overfitting” bezeichnet.
Die Tabelle zeigt anhand eines Ausschnitts beispielhaft wie die Auswertung der Testdaten vereinfacht aussehen.
Jede Zeile gehört zu einer Kategorie. Die Spalte Support enthält die Anzahl der Testdaten zur jeweiligen Kategorie. Die unterste Zeile gibt die Metriken für die Kategorien gemeinsam an. Diese exemplarische Auswertung bezieht sich auf das Modell, das wir für die Kategorisierungsebene Bezugsbereich 1 trainiert haben.
Mit den Metriken Precision und Recall lässt sich die Qualität von vorhergesagten Kategorisierungen quantifizieren. Precision ist ein Maß für die Genauigkeit und ist als die relative Häufigkeit definiert, dass eine Klasse richtig ist, wenn sie vorhergesagt wird. Recall hingegen ist die Trefferquote. Sie gibt die relative Häufigkeit an, dass ein Klasse auch als solche vorhergesagt wird. Der F1-Score ist eine Art Kombination von Precision und Recall. Gemeinsam geben diese Metriken soliden Aufschluss über die Performance bei Klassifikatoren.
precision recall f1-score support
Airport 0.81 0.82 0.81 4060
Customer Service 0.74 0.83 0.78 118
Flight 0.81 0.75 0.78 8670
Reservation 0.61 0.72 0.66 2416
... ... ... ... ...
accuracy 0.68 19145
weighted avg 0.69 0.68 0.68 19145Zudem sind beispielsweise 81% der Texte, die die KI mit Label “Airport“ versehen hat, auch tatsächlich (also vom Sachbearbeiter klassifiziert) “Airport”. Recall von 82% bei “Airport” bedeutet, dass 82% aller Texte, die tatsächlich “Airport” sind, die KI auch als solche erkannt hat.
Nachdem wir beobachtet haben, dass die Modelle gute Ergebnisse liefern, haben wir die Menge der Lerndaten vervierfacht und die Schritte von oben wiederholt. Dadurch wurden die Modelle besser und vor allem robuster gegenüber Sonderfällen.
Leistungsfähigkeit der KI nachvollziehbar machen
Für Menschen, die sich nicht täglich mit den Themen Künstliche Intelligenz und Automatisierung beschäftigen, ist Machine Learning „Voodoo“. Damit wir Vertrauen in die Leistungsfähigkeit des ML Systems aufbauen und die Ergebnisse nachvollziehbar und persönlich testbar machen, haben wir ein kleines Programm erstellt, mit dem
- der Text des Kunden und die erfasste Kategorisierung eingefügt,
- das ML Modell mit den Daten ausgeführt,
- die Kategorisierung durch das Modell und vom Sachbearbeiter ausgegeben und
- das Ergebnis kommentiert
wird.
Ein Programm zeigt den Ablauf
Zu Beginn kopiert das Programm den Kundentext und die vom Sachbearbeiter in targenio erfasste Kategorisierung in das Feld „Sachverhalt“. Der ML Algorithmus wendet dann sein antrainiertes Wissen an. Das wird in der linken Spalte die Kategorisierung des ML angezeigt. In der rechten Spalte ist die vom Sachbearbeiter erfasste Kategorisierung gegenübergestellt, so ist ein unmittelbarer Vergleich zwischen Mensch und Maschine möglich:
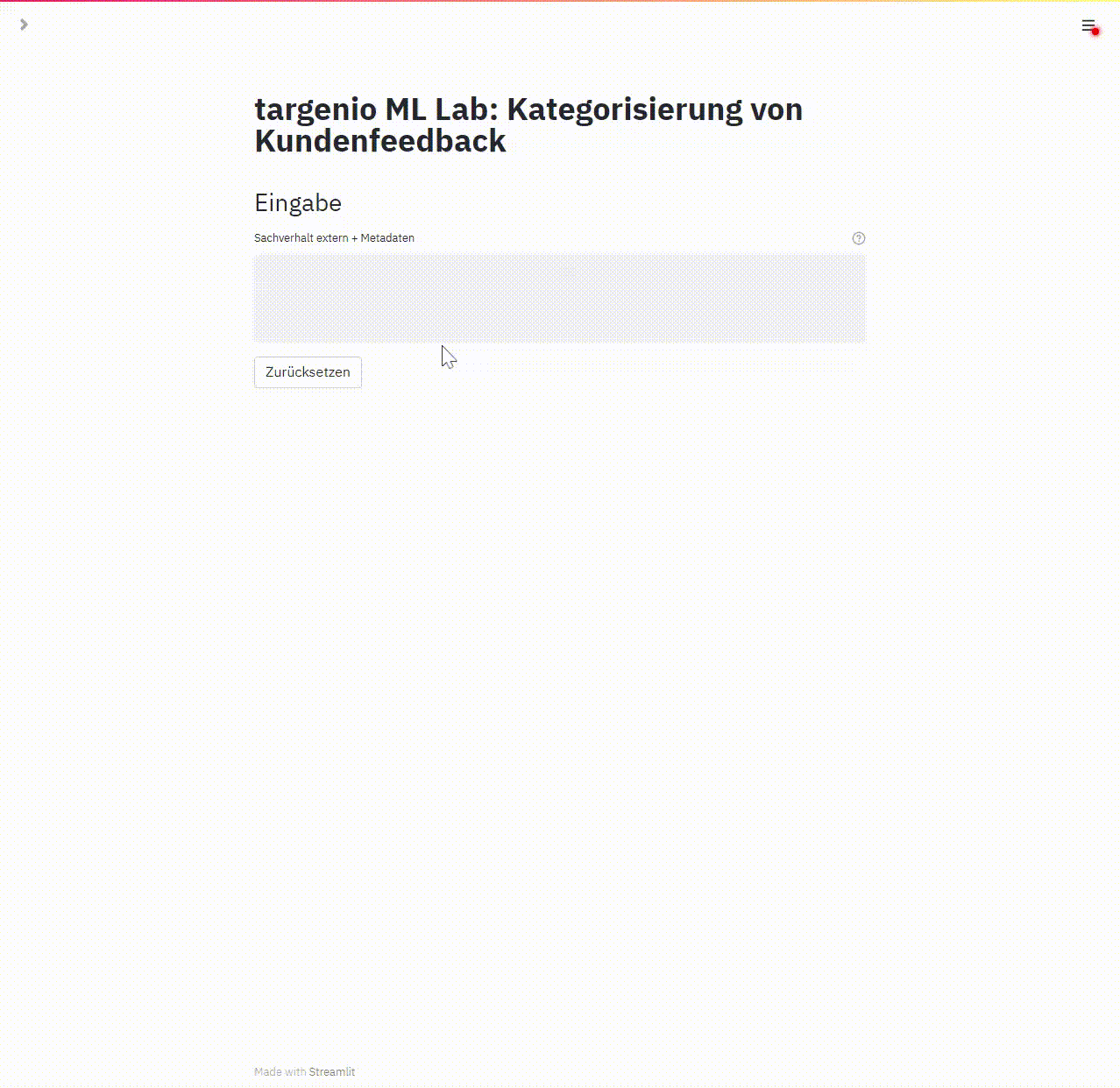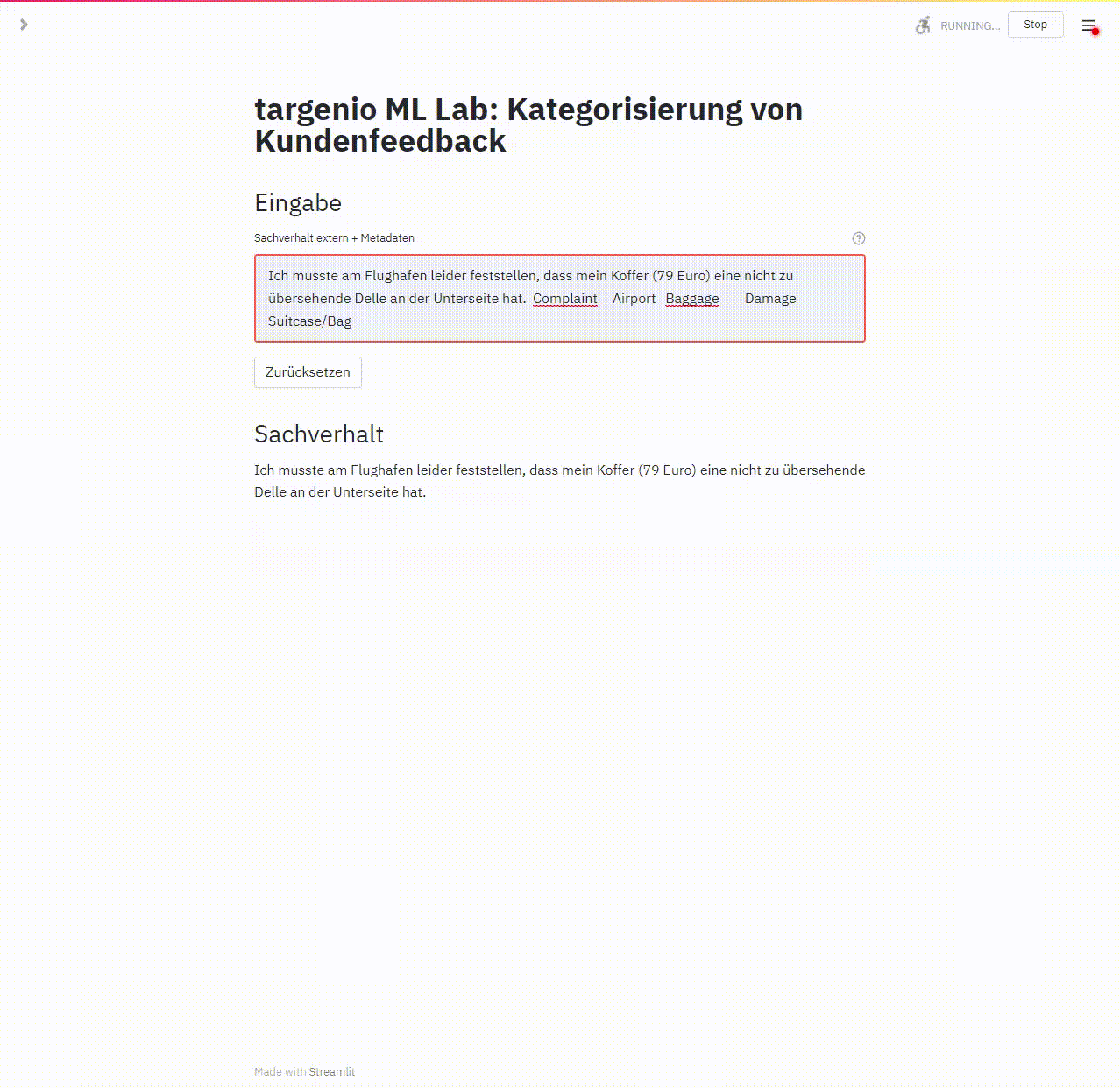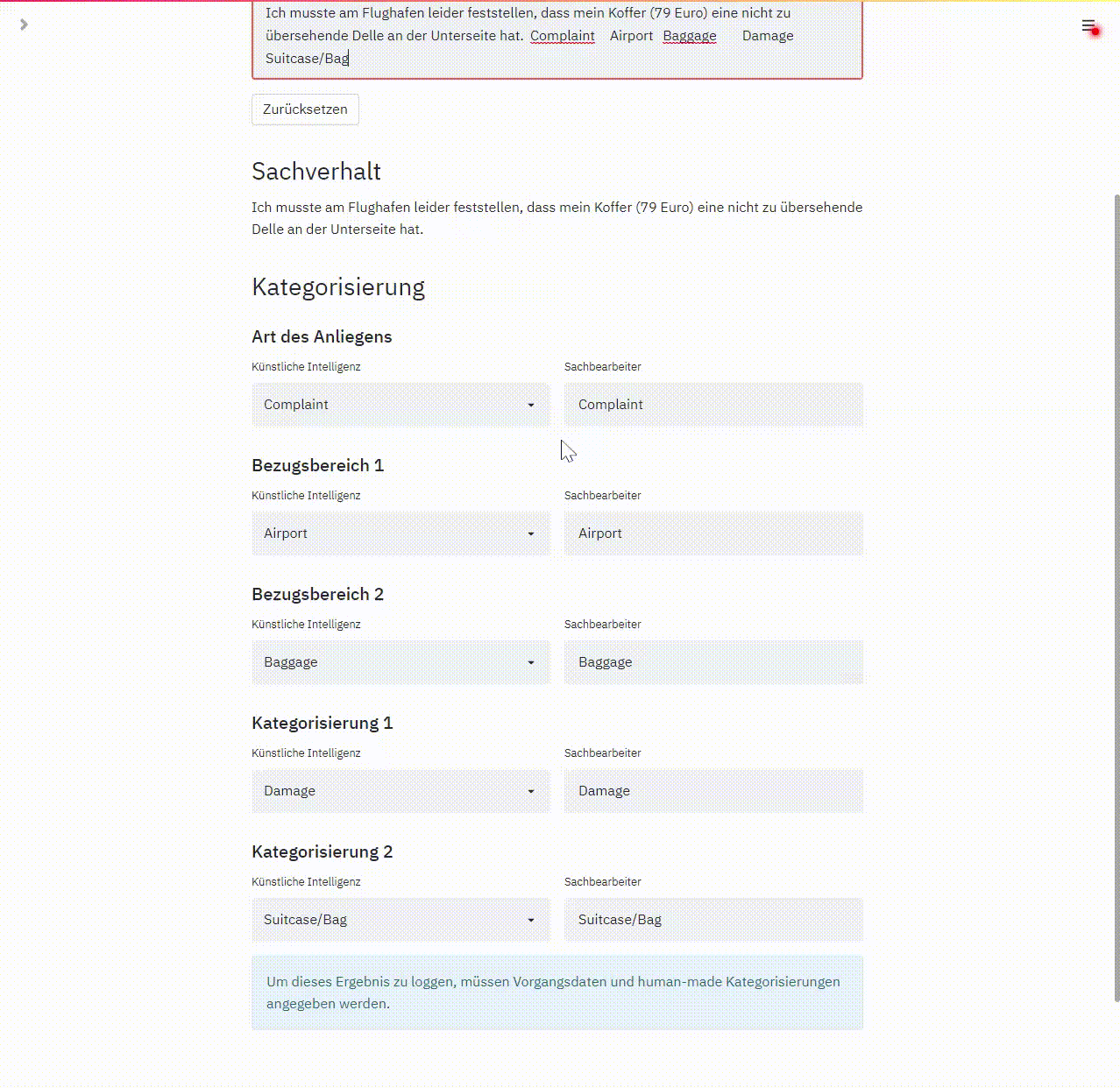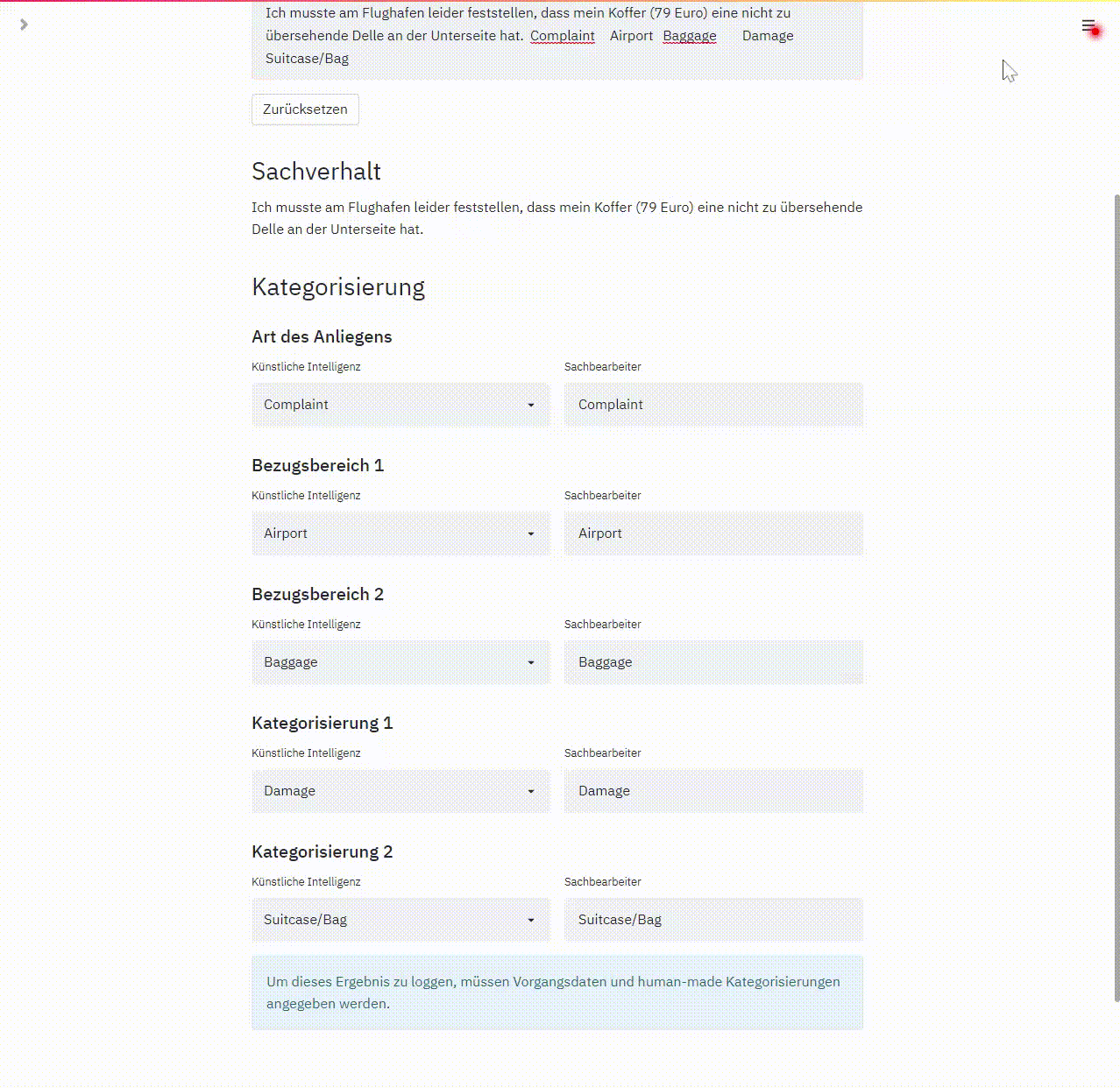
Da wir dieses Programm auch für unsere qualitativen Tests verwendet haben, ist zusätzlich zu jedem Testlauf der Name des Testers, das Testergebnis und eine Referenz auf den Original-Vorgangsdatensatz dokumentiert.
Das komplette Testsetup ist in folgendem Architekturbild dargestellt:
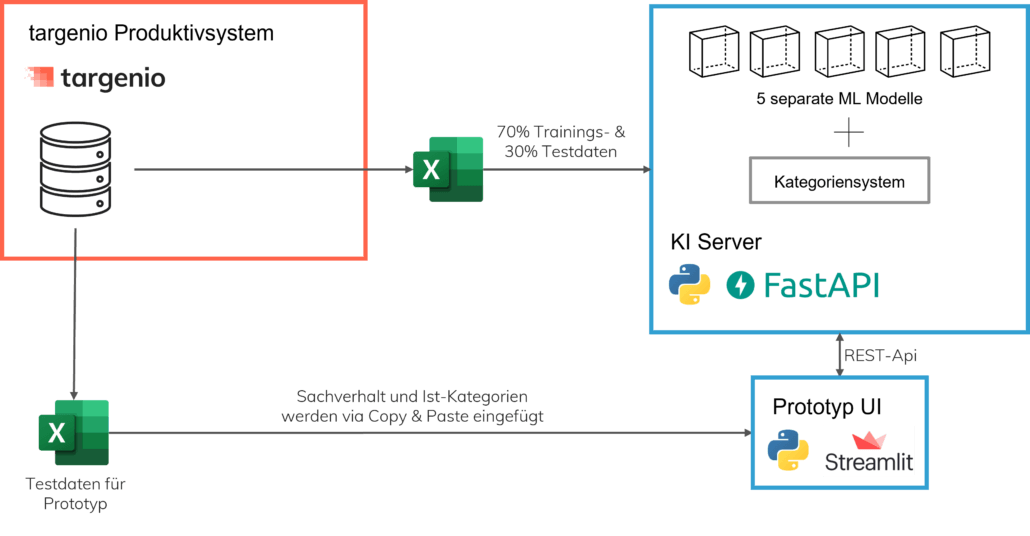
Nach einigen Testläufen hat sich für uns folgendes Bild herauskristallisiert: Das von uns trainierte Modell kategorisiert einen Großteil der Kundentexte genauso, wie die Sachbearbeiter im Kundenservice. Bei einem geringen Anteil der Testdatensätze ermittelte die KI eine fehlerhafte Kategorie. Und bei einem weiteren Großteil der getesteten Sachverhalte wich das Ergebnis der KI zwar von der Kategorisierung des Kundenservicemitarbeiters ab, war aber fachlich nicht falsch, sondern nur anders.
Als Ursachen für fehlerhaft klassifizierte Sachverhalte haben wir eine zu geringe Anzahl an Testfällen in den Lerndaten und redundante Einträge im Kategoriensystem identifiziert; daraus haben wir zwei Optimierungsschritte abgeleitet: Signifikante Erhöhung der Lerndaten und Priorisierung der Ergebnisse anhand der Struktur des Kategorienbaums in targenio.
ML Anwendung optimieren
Wie oben beschrieben, hatten wir uns entschieden, für jede Ebene der Kategorisierung ein eigenes Modell zu trainieren. Dadurch konnte der Algorithmus Kombinationen von Kategorien erlernen, die in der Baumstruktur des Kategoriensystems von targenio gar nicht auswählbar sind.
Um dieses Problem zu heilen, haben wir uns eine Funktion der Modelle zunutze gemacht, dass nämlich die Modelle eine Wahrscheinlichkeit für alle möglichen Kategorien der jeweiligen Kategorienebene ausgeben. Diese Wahrscheinlichkeitsangaben haben wir einfließen lassen, indem wir für Gesamtvorhersagen diejenige Kategorisierung wählen, die größtmögliche Gesamtwahrscheinlichkeit (das Produkt der fünf einzelnen Wahrscheinlichkeiten) hat und gleichzeitig mit dem Kategorienbaum konsistent ist. Dieser Abgleich der Vorhersagen mit dem Kategoriensystem machte die KI als Ganzes robuster.
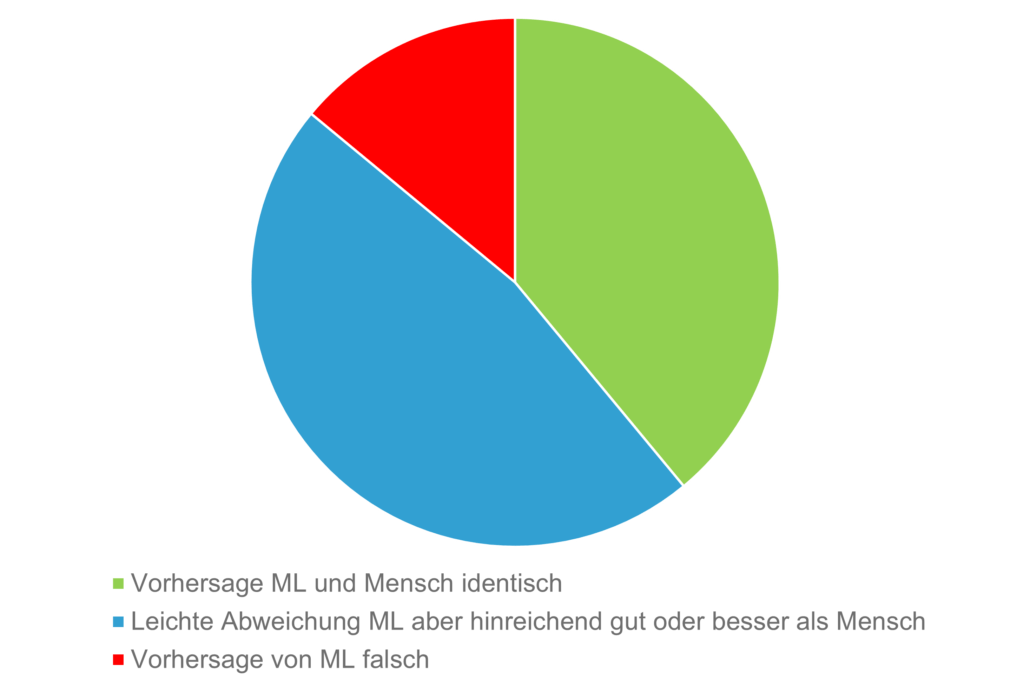
Nach dem Abgleich mit dem targenio Kategorienbaum und der Ausweitung der Lerndaten haben wir die Optimierung des Modells realisiert. Das führte dazu, dass die KI weit über 80% der Kundentexte richtig (in Sinne: entspricht der vom Sachbearbeiter vorgenommenen Kategorisierung) klassifiziert hat.
Beantwortung der Forschungsfrage, Lessons learned und Perspektive
Unser Projekt hat gezeigt, dass wir mit der heute verfügbaren Machine Learning Technologie unstrukturierte Kundentexte auf ein umfangreiches Kategoriensystem mappen können. Hierbei stimmen die Ergebnisse der KI zu mehr als 80 % mit den von Sachbearbeitern erfassten Kategorisierung überein.
Sind > 80 % Übereinstimmung ausreichend, um ML produktiv im Kundenservice einzusetzen und die Mitarbeiter bei der Bearbeitung von Kundenanliegen zu entlasten? Ist die Qualität der ML Algorithmen also hoch genug?
Nach unserer Meinung ein eindeutiges JA!
Dieses “JA” stützt sich auf Überlegungen und Erkenntnissen, die wir im Laufe des Projekts und mit der intensiven Beschäftigung der Daten gesammelt haben:
- Der verwendete Kategorienbaum ist in sich nicht eindeutig und widerspruchsfrei. Zudem ist er nicht ausreichend ausgewogen und “überbetont” bestimmte Sachverhalte bei gleichzeitigem Negligieren ganzer Bereiche.
- Die Anwendung des Kategorienbaums erfolgt durch eine große Anzahl von Sachbearbeitern mit unterschiedlichen Skills und Erfahrungen. Von daher ist nicht anzunehmen, dass ein- und derselbe Kundentext durch verschiedene Mitarbeiter identisch klassifiziert wird.
- Selbst bei gleich hoher Qualifikation und Motivation der Mitarbeiter verbleiben Zweifelsfälle, die legitimerweise unterschiedlich interpretiert und ausgelegt werden können.
Stellt man diese Überlegungen der aktuell ermittelten Übereinstimmung von 80 % gegenüber, dann ergibt sich ein akzeptables Niveau, zumal die KI Texte neutral, reproduzierbar und in gleichförmig klassifiziert.
Welche sonstigen Erkenntnisse haben wir durch unser Projekt gewonnen?
Wie zu erwarten, bestimmt die Menge und Qualität der Daten die Leistungsfähigkeit der KI. So konnten wir durch eine Erhöhung der Lerndaten von 100.000 auf 400.000 Datensätze eine signifikante Verbesserung der Ergebnisse erzielen. Die eingesetzten, frei verfügbaren open source Modelle erlauben einen wirtschaftlichen Einsatz von künstlicher Intelligenz für Aufgabenstellungen im Kundenservice. Durch geeignete Maßnahmen können die Ansprüche des Datenschutzes eingehalten werden.
Wie sind nun die Perspektiven?
Künstliche Intelligenz und Machine Learning sind bereit für den produktiven Einsatz. Die Treffsicherheit unseres ML Modells ist ausreichend hoch, um damit die nächste Ebene der Automatisierung zu erreichen und neue Use Cases umzusetzen. Welche das sind, zeigen wir in unserem nächsten Artikel dieser Serie auf.
Takeaway
- Das Entwickeln eines Kategoriensystems, das zugleich nützlich und einfach ist, ist eine herausfordernde Aufgabe.
- Unsere Versuche zeigen, dass KI-Algorithmen heute sehr gut und treffsicher unstrukturierte Texte zu Kategorien zuordnen können.
- Mit dem Einsatz von Open Source Modellen kann KI heute leicht in Anwendungen integriert werden und die Effizienz bei der Bearbeitung von Kundenanliegen steigern.


 targenio
targenio targenio
targenio

