Seit über zehn Jahren vertraut Condor auf die Expertise von targenio. Auf Basis dieser guten Zusammenarbeit lag es nahe, die bestehende Software mit targenio AIR abzulösen, um in Sachen Kundenservice State of the Art zu sein. Herausragend dabei waren viele Zahnräder, die ineinandergegriffen haben. Zu betonen ist allerdings die Kürze der Zeit, nur fünf Monate, in der das alte System abgelöst wurde. „Zielsetzung war das System im ersten Schritt ohne individuelle Programmierung einzuführen“, erklärt Marcus König, Geschäftsführer der targenio GmbH, im Gespräch. „Da targenio AIR eine Standardlösung für den Kundenservice bei Fluglinien ist, konnten wir das System sehr zügig auf die Beine stellen und in Betrieb nehmen.“ Diese Standardeinführung spart Zeit bei der Implementierung und ermöglicht weiteres Optimieren während des laufenden Betriebs.
Je mehr Schnittstellen, desto besser die Automatisierungen bei Condor
Beim Anbinden von Schnittstellen ist targenio AIR höchst flexibel. Es lässt sich problemlos in bestehende Systemlandschaften integrieren und zeigt spätestens dann seine wahre Stärke. Je mehr Systeme angebunden werden, desto leichter können Arbeitsabläufe automatisiert und das Arbeitsvolumen erhöht werden. „Die Vorteile werden nach und nach sichtbarer,“ so Torsten Hornig, einer unserer Ansprechpersonen von Condor, „Allein die Performance hat sich immens gebessert aber auch die übersichtlichere Maskenansicht hilft bei der schnellen Bearbeitung von Vorgängen. Denn es sind genau die Inhalte sichtbar, die auch relevant für den Vorgang sind.“
Bei Condor war zum GoLive die Anbindung von drei Schnittstellen essentiell, die zu ersten Automatisierungen beitragen. Damit ist es möglich, Auszahlungsabwicklungen und die Voucherausgaben über targenio AIR abzuwickeln. Eine wichtige Neuerung ist die vollautomatische Entscheidung und Verarbeitung der so genannten „3 Stunden – Delays“ nach EU261. Der Automat prüft in Zukunft selbständig die Berechtigung und veranlasst nach positiver Prüfung die Überweisung des Geldes. Damit können sich die Customer Service Manager künftig effizienter auf Sonderfälle und herausfordernde Anfragen konzentrieren.
Migration, dank Cloudlösung, leicht gemacht
Der Livegang des Systems erfolgte in mehreren Stufen, um eine möglichst geringe Wartezeit auf ihre Antworten sicherzustellen. Parallel zur laufenden Lösung wurde die neue Version aktiv geschalten, damit das Projektteam sich an die Neuerungen sukzessive herantasten konnte. Im Anschluss kamen nach und nach die zu migrierenden Fälle sowie das schrittweise Freischalten des restlichen Kundenserviceteams.
Die Migration der Daten war der sensible Part vor der vollständigen Inbetriebnahme des neuen Systems. Sicherheit gab dabei die Umstellung der Software auf eine reine Cloudlösung. Das heißt, deren Datenbanken liegen ausschließlich in der Cloud. Deshalb ist die Skalierung der Ressourcen variabel und schnell an neue Anforderungen anpassbar. In kürzester Zeit konnten gewünschte Kapazitäten freigeschalten und die Datenmigration aller notwendiger Vorgänge so kurz wie möglich gehalten werden. „Aufgrund der kurzen Zeit, die wir hatten, haben wir das Beste aus der Situation gemacht und das hat wirklich super geklappt,“ erläutert Hornig.
Wie erfolgreich dieses Konzept war, zeigt sich in der Gewährleistung einer so genannten Zero-Down-Time der Systeme. Der Übergang von alter auf neue Version verlief so fließend, dass kundenseitig keine Auffälligkeiten zu verzeichnen waren.
targenio AIR ist die Branchenlösung für den Kundenservice von Airlines
targenio AIR bringt von sich aus branchenspezifische Prozessvorschläge mit, wodurch der schnelle Umstieg von alt auf neu hervorragend gemeistert werden konnte. Mit der Lösung ist es den Agenten möglich, die Kommunikation mit ihren Kunden vollständig in einem System zu bearbeiten. Egal, ob die Anfragen per E-Mail, Brief oder ein Formular auf der Website eingereicht werden: Alle Informationen laufen über entsprechende Schnittstellen in targenio AIR zusammen. Die Agenten sehen die komplette Kommunikation in einer Übersicht, inklusive aller notwendigen Informationen rund um die Flüge. Hornig freut sich über diese Neuerung: „Unser Ziel ist es, dass die Agenten in gar keine Drittsysteme mehr springen müssen, um Kundenfragen zu beantworten. Dafür werden wir demnächst weitere Systeme von Condor anbinden.“
Nicht nur die Anbindung aller Systeme markiert eine Verbesserung für die Agenten, weiß Hornig: „Auch die Textbausteine und E-Mail-Vorlagen sind fortschrittlicher für uns und helfen bei der Effizienz.“ Dank dieser können die Agenten aus einer individuell gestalteten Vorlagensammlung, und je nach Fall automatisch vorgeschlagenen Elementen, die jeweiligen Bausteine für hochwertige Antworten wählen. Das garantiert den Kunden durchgängig qualitativ erstklassigen Kundenservice.
Sarah Bieker, ebenfalls Mitglied des Projektteams, unterstreicht die Vorteile unserer Software für Airlines: „targenio AIR ist eine Lösung, bei der Airlines nicht bei null anfangen müssen. Viele Airlines haben, trotz individueller Unterschiede, ähnliche Prozesse.“
Standardlösung und Individualisierung gehen Hand in Hand
Diese ähnlichen Prozesse führten zur Standardlösung, die dabei individuelle Bedürfnisse nicht außen vorlässt. „Natürlich bedeutet das Implementieren einer Standardlösung wie targenio AIR nicht, dass wir keine Individualisierungen vornehmen können. Im Gegenteil, das Team aus dem Kundenservice kann nun evaluieren, was sie brauchen. Diese individuellen Anforderungen bringen wir dann nach und nach in das laufende System ein“, ergänzt König mit Blick auf die die kommende Zeit.
Aus diesem Grund planen die Verantwortlichen von Condor zusammen mit targenio schon jetzt die weiteren Schritte. Im Zentrum des Interesses bleibt die Automatisierung weiterer Vorgänge, damit sich das Team aus dem Kundenservice auf komplexe Sachverhalte konzentrieren kann.
Wir danken dem Team von Condor für dieses Projekt und die sehr gute sowie offene Zusammenarbeit, die uns auch in Zukunft zu neuen Projekten abheben lässt.
https://targenio.de/wp-content/uploads/2024/03/230605_CONDOR_20_ECONOMY_CLASS_036_LowRes-scaled-1.jpg19202560Liam Flohryhttps://targenio.de/wp-content/uploads/2024/02/targenio-logo.svgLiam Flohry2024-01-11 07:23:312024-03-27 13:44:41Condor setzt im Kundenservice in Zukunft auf targenio AIR
Qualitätssicherung ist in der heutigen Softwareentwicklung von entscheidender Bedeutung. Sie garantiert nicht nur eine möglichst fehlerfreie Funktionalität von Anwendungen, sondern auch die Zufriedenheit der Endnutzer. Eine effiziente Möglichkeit, die Qualität unserer Software sicherzustellen, ist die Verwendung der imbusTestBench. Unser Mitarbeiter Jürgen hat es treffend formuliert: „Die Verwendung der TestBench ermöglicht uns eine effektive Pflege unserer Softwaretestfälle, was für mehr Zufriedenheit bei unseren Kunden im digitalen Kundenservice sorgt.“ In diesem Blogbeitrag werden wir näher darauf eingehen, warum imbus für uns ein vertrauenswürdiger Partner ist und wie deren Tool TestBench dazu beiträgt, die Qualität unserer Software zu gewährleisten.
Regionale Nähe und effiziente Kommunikation
Da die Firma imbus ein regionaler Ansprechpartner ist, gewährt diese Nähe eine schnelle und unkomplizierte Kommunikation, sowohl virtuell als auch vor Ort. Als führender Anbieter im Bereich Testing in Deutschland ist diese persönliche Betreuung ein klarer Vorteil in unseren Augen. Unsere Erfahrung zeigt, dass die enge Zusammenarbeit und der persönliche Kontakt die Effizienz steigern und Problemlösungen beschleunigen.
Automatisierte Testfälle für eine hohe Effizienz
Die Automatisierung von Testfällen ist ein Schlüsselaspekt in der Qualitätssicherung von Software. Die TestBench ermöglicht uns, automatisierte Testfälle einfach zu erstellen und zu verwalten. Wir haben Selenium (OpenSource, Java) in Verbindung mit der TestBench als Testautomatisierungsframework im Einsatz. Darüber hinaus können wir unsere Automatisierung in Jenkins integrieren, um eine Continuous Integration Pipeline für unsere Projekte aufzubauen. Diese Funktionalität spart nicht nur Zeit, sondern gewährleistet auch eine konsistente und wiederholbare Testdurchführung. Die Testfälle sind in einer „excel-artigen“ Struktur dargestellt, was ihre Lesbar- und Nachvollziehbarkeit verbessert.
Variantenmanagement für mehr Flexibilität
In der Softwareentwicklung müssen unsere Testfälle oft in verschiedenen Projekten oder in verschiedenen Sprachen wiederverwendet werden. Die TestBench bietet dafür ein effizientes Variantenmanagement. Alle Testfälle werden in einem gemeinsamen Repository gespeichert und können einfach in den verschiedenen Projekten verwendet werden. Die einfache Auswahl der gewünschten Testvarianten kann durch Checkboxen oder Variantenmarker erreicht werden. Dieses Feature trägt dazu bei, den Verwaltungsaufwand zu minimieren und die Wiederverwendbarkeit von Testfällen zu maximieren.
Key-Word-Driven Testing für Wartbarkeit und Effizienz
Eine weitere unverzichtbare Eigenschaft der TestBench ist das Key-Word-Driven Testing. Diese Methode vereinfacht die Wartung von Produkt- und Projekttestfällen erheblich. Sie führt zu einer klaren Trennung von Testdesign und Testimplementierung. Mit Key-Word-Driven Testing wird die Testerstellung erleichtert und beschleunigt, da vordefinierte Schlüsselwörter für die Erstellung neuer Tests verwendet werden. Dies führt zu einer höheren Effizienz und Wartbarkeit der Testfälle, da Änderungen im Testdesign keine umfangreichen Anpassungen des Testimplementierungscodes erfordern.
Fazit: Strukturierte Qualitätssicherung
Die TestBench von imbus bietet uns eine strukturierte und effiziente Qualitätssicherungslösung. Die vielfältigen Möglichkeiten der Berichterstattung gewährleisten eine kundenspezifische Anpassung von Berichten und eine einfache Auswertung der Testergebnisse. Die Erstellung von Testfällen ist dank Funktionen wie Drag & Drop unkompliziert und benutzerfreundlich. Mit der TestBench erreichen wir eine hohe Qualität unserer Software und gewährleisten die Zufriedenheit unserer Kunden.
Wir sind stolz darauf, mit einem vertrauenswürdigen Partner wie imbus zusammenzuarbeiten, deren Software unsere Anforderungen erfüllt und die uns bei der Bereitstellung hochwertiger Software unterstützt.
https://targenio.de/wp-content/uploads/2024/03/TestBench-in-Benutzung.jpg7681024Liam Flohryhttps://targenio.de/wp-content/uploads/2024/02/targenio-logo.svgLiam Flohry2023-10-25 07:41:492024-04-08 09:05:28Mit der TestBench sorgen wir für eine hohe Qualität unserer Software
Der Begriff No Code[1] / Low Code[2] (NCLC) wurde erst 2014 von John Rymer geprägt. Vor einigen Jahren zeichnete sich dann ab, dass das Thema einen großen Aufschwung nehmen würde. Mittlerweile ist es in aller Munde und wird in vielen Unternehmen als zwingende Notwendigkeit für die Zukunftsfähigkeit gesehen. Das sieht auch die Low-Code Association e.V. so, die 2022 gegründet wurde und den Weg für dieses Thema grundlegend in Deutschland ebnen will. Um das zu schaffen, hat sie den German Low-Code Day ins Leben gerufen, auf dem unsere Kollegen Marcus und Thomas anwesend waren.
Bisher gestaltete sich der Weg zu einer neuen Anwendung eher klassisch. Wollte ein Fachbereich im Unternehmen eine neue Anwendung einführen, musste dieser sorgfältig planen: es brauchte einen sorgfältig ausgefeilten Anforderungskatalog, auf dessen Basis eine die entsprechende Software ausgewählt wurde, um sie anschließend im Fachbereich zu testen. Das versetzt den Fachbereich in ein mentales Wartezimmer, bevor man mit der gewünschten Lösung bereits loslegen kann.
No-Code und Low-Code-Plattformen sind auf dem Vormarsch
Der NCLC-Ansatz hilft Unternehmen aus diesem Anwendungs-Wartezimmer heraus. Zwar liegen klassische Softwareentwicklungsplattformen bezogen auf die Zahl der Einsatzunternehmen immer noch vor den NCLC-Plattformen, und sind je nach Fachbezug auch zwingend notwendig. Der Vorsprung ist allerdings nur noch marginal und wird sehr schnell aufgeholt sein. Das betrifft sowohl die Software-Entwicklung, als auch die Prozessmodellierungen, die nur noch über grafische Benutzeroberflächen erstellt werden. Wasserfallmethoden gehören immer mehr der Vergangenheit an.
Fünf Hauptgründe für den Einsatz von No-Code / Low-Code
Beschleunigung der Softwareentwicklung steht bei vielen Unternehmen im Mittelpunkt ihrer Low -Code / No-Code-Strategie. Mit 39 Prozent der Befragten, die sich auf dieses Ziel konzentrieren, streben sie an, ihre Softwareprojekte schneller umzusetzen und Innovationen rascher auf den Markt zu bringen.
Die Erhöhung der Prozesseffizienz ist ein weiterer Schwerpunkt für viele Unternehmen, wobei 37 Prozent ihre Arbeitsabläufe optimieren wollen. Effizientere Prozesse können nicht nur die Produktivität steigern, sondern auch die Kosten senken und die Wettbewerbsfähigkeit erhöhen.
Kostensenkung ist für 34 Prozent der befragten Unternehmen von zentraler Bedeutung. In wirtschaftlich anspruchsvollen Zeiten suchen viele Organisationen nach Möglichkeiten, ihre Ausgaben zu reduzieren, ohne dabei die Qualität ihrer Produkte oder Dienstleistungen zu beeinträchtigen.
Zudem sehen 33 Prozent der Unternehmen großes Potenzial im sogenannten „Citizen Development„. Dies bedeutet, dass nicht nur IT-Experten, sondern auch Fachanwender Anwendungen entwickeln können. Diese demokratisierte Herangehensweise ermöglicht es, schneller auf geschäftliche Anforderungen zu reagieren.
Schließlich ist die Steigerung der Usability von Anwendungen ein wichtiger Faktor, den ein Drittel der Unternehmen in den Fokus rückt. Eine benutzerfreundliche Oberfläche und eine angenehme Nutzererfahrung sind entscheidend, um Kunden und Mitarbeiter zufriedenzustellen und die Akzeptanz neuer Technologien sicherzustellen.
Vorteile von Low Code / No Code:
Auf Basis dieser Informationen und unserer Erfahrung mit renommierten Firmen, können wir folgende Vorteile für die jeweilige Berufsgruppe festhalten:
Unternehmen:
Beschleunigung der Digitalisierung im Unternehmen.
Förderung der agilen Organisation und Kultur durch Schwarmintelligenz, dezentrale Verantwortung und Abbau von Silos.
Verantwortliche von Prozessen:
Schnellere Markteinführung (time to market).
Reduzierter Aufwand und Kosten.
Möglichkeit zur Implementierung spezifischer und differenzierender Lösungen.
Mitarbeiter in den Fachabteilungen:
Motivation zur Optimierung und Automatisierung ihrer Arbeit.
Chancen zur persönlichen Weiterentwicklung im Kontext der Digitalisierung.
IT-Abteilungen:
Entlastung von Mitarbeiterkapazität und Budgets.
Verlagerung der Verantwortung für Lösungen in die Fachbereiche.
Generelle Nutzen:
Schnelle Verfügbarkeit von automatisierten Prozessen durch breiteres Personal, das Prozesse schneller optimiert.
Verteilung von Zuständigkeiten auf verschiedene Abteilungen, einschließlich Beratung und Testung.
Nutzung vorgefertigter Benutzeroberflächen und UX-Funktionen für beschleunigte Anwendungsentwicklung.
Integration identischer Funktionen in verschiedenen Anwendungen zur Zeitersparnis.
targenio bietet erste Möglichkeiten auf LCNC
targenio ist ein Unternehmen, das sich auf die Bedürfnisse im Kundenservice spezialisiert hat. Unsere Software ist äußerst vielseitig, insbesondere im Kundenservice-Bereich. Sie ermöglicht individuell konfigurierbare Workflows, die den Anforderungen von Kundenservice-Managern gerecht werden. Bereits lange bevor der Begriff LCNC zum Trendthema wurde, haben wir No-Code-Funktionen in unsere schlanken Softwarelösungen integriert. Dabei haben wir den Workflow- und Katalogmanager sowie den Maskendesigner entwickelt und ausgebaut. Wir setzen diesen Ansatz konsequent fort, um eine umfassende Lösung für Citizen Developer zu schaffen, die eine 360-Grad-Abbildung ermöglicht. „Low-Code-Tools und -Plattformen sollten die Softwareentwicklung ganzheitlich unterstützen, einschließlich Spezifikation, Integration, Test, Dokumentation, Deployment, Betrieb und Pflege“, vertritt Thomas, unser Leiter Business Development. „Bei der Verbesserung dieser Werkzeuge wird Künstliche Intelligenz in Zukunft entscheidend beitragen. Das habe ich unter anderem von der Veranstaltung am 27.09. in Hannover mitgenommen.“
Für wen sich targenio eignet
Davon ausgehend können wir natürlich ganz klar bestimmen, für welche Zielgruppen unsere Kundenservice Software am besten geeignet ist.
Lieferkettenmanager
Resiliente Lieferketten sind für Unternehmen in der heutigen Zeit maßgeblich für eine durchgängige Produktion. Sobald eine Lieferkette nur minimal hakt, gerät der komplette interne Ablauf ins Stocken und vergeudet relevante Ressourcen. Genaue Analysen, die alte und neue Daten miteinander kombinieren, bieten robuste datengestützte Erkenntnisse, womit eine verbesserte Modellierung und Überwachung von Lieferkettenabläufen gewährleistet wird. Eine bessere Rück- und Nachverfolgbarkeit der Supply Chain bietet Transparenz für schnellere Reaktionen auf stockende Lieferketten.
Kundenservicemanager
Manager im Kundenservice freuen sich, wenn die Kundenzufriedenheit verbessert wird. Denn eines ist bekannt: Sind die Kunden zufrieden, sinkt die Beschwerderate. Mit individuellen Festlegungen von Workflows gibt es schnellere Möglichkeiten, individuell zu antworten und Kunden zufriedenzustellen. Ganz nebenbei sind die Kundenanfragen messbar. So kann zügig auf sprunghaft ansteigende Anliegen reagiert und ihnen präventiv entgegengesteuert werden.
Berater im Kundenservice
Berater nehmen mit LCNC eine größere Rolle ein. Ihr fundiertes Wissen können sie in kürzester Zeit unterstützend in Unternehmen einbringen. Sie müssen nicht auf Entwickler warten, sondern setzen Anwendungen den Anforderungen entsprechend unverzüglich selbst um.
Interesse geweckt?
Wenn dieses Thema dein Interesse geweckt hat und du mehr darüber erfahren möchtest oder darüber sprechen möchtest, freuen wir uns sehr auf deine Kontaktaufnahme. Unser Team steht bereit, um alle deine Fragen zu beantworten und weitere Informationen bereitzustellen. Zusammen können wir die Möglichkeiten, die unsere Softwarelösungen bieten, ausführlich erörtern und herausfinden, wie sie am besten zu deinen speziellen Anforderungen passen. Zögere also nicht, uns zu kontaktieren, damit wir gemeinsam die besten Lösungen für deine Bedürfnisse im Kundenservice finden können.
[1] No-Code ist eine Methode oder Plattform zur Erstellung von Softwareanwendungen. Dort ist überhaupt keine herkömmliche Programmierung erforderlich. Es werden visuelle Werkzeuge und Drag-and-Drop-Elemente verwendet, um Anwendungen zu erstellen. Benutzer brauchen keine tiefgreifenden Codierungskenntnisse. Dieser Ansatz ermöglicht es Nicht-Technikern, so genannten Citizen Developern, Anwendungen zu erstellen, indem sie vorgefertigte Module und Vorlagen nutzen. Diese Methode erhöht die Entwicklungsgeschwindigkeit und bindet Menschen ohne formelle Programmierkenntnisse in den Erstellungsprozess ein.
[2] Low-Code ist eine Softwareentwicklungsplattform oder -methode, mit der Entwickler Anwendungen mit minimalem manuellem Programmieraufwand erstellen. Sie verwenden visuelle Schnittstellen und Drag-and-Drop-Tools, um Anwendungslogik, Datenbankintegration und Benutzeroberflächen zu gestalten. Dies ermöglicht es, schneller und mit weniger umfassenden Programmierkenntnissen Anwendungen zu erstellen. Das beschleunigt den Entwicklungsprozess und überbrückt die Kluft zwischen technischen und nicht-technischen Benutzern.
https://targenio.de/wp-content/uploads/2024/03/adi-goldstein-mDinBvq1Sfg-unsplash-scaled-1.jpg14702560Liam Flohryhttps://targenio.de/wp-content/uploads/2024/02/targenio-logo.svgLiam Flohry2023-10-04 11:17:242024-04-05 10:24:01Warum an No Code / Low Code kein wirtschaftlicher Weg mehr vorbei führen wird?
Sommerzeit ist Reisezeit – und gleichzeitig die heißeste Zeit in der Customer Service Abteilung. Während der Hochkonjunktur müssen sich die Kundenservicemitarbeiter zahlreichen Widrigkeiten stellen. Damit schlechte Schlagzeilen wie „Flug-Entschädigung: die Tricks der Airlines“ der Vergangenheit angehören, haben wir die fünf größten Herausforderungen im Sommer zusammengestellt. Und anschließend herausgearbeitet, wie Agents im Kundenservice diesen, trotz des enorm hohen Aufkommens, weiterhin adäquat und wohlwollend begegnen können.
Diese fünf Herausforderungen bewirken hitzige Arbeitsstunden
Niemand möchte seine Arbeitszeit im Dauerstress verbringen. Bei einigen Kundenservice Abteilungen ist das im Sommer allerdings Alltag. In dieser hitzigen Jahreszeit erschweren folgende fünf Themenblöcke überwiegend die Arbeitszeit der Kundenservice Mitarbeitenden.
1. Hohe Kundenanfragen
Die Sommerwochen sind die Zeit, in der die Airlines den Umsatz des Jahres machen. Die Menschen sind in den langersehnten Jahresurlaub unterwegs und nutzen dafür überwiegend den Flieger. Das führt zu einer erhöhten Nachfrage der Flugtickets und entsprechenden Anfragen im Kundenservice, da der Urlaub für die Familien ein einmaliges und emotionales Ereignis ist. Aufgrund dessen sollte alles perfekt und alle Fragen im Vorfeld geklärt sein. Je höher die Frequenz solcher Anfragen ist, desto länger kann es zu Wartezeiten für eine Antwort kommen. Die Arbeitszufriedenheit ist dadurch enorm beeinträchtigt. Das wirkt sich entsprechend auf die Kundenzufriedenheit aus.
2. Flugverspätung und Stornierungen
Im Sommer können Wetter, Flughafenüberlastung, Fehler in den Prognosen sowie Planungen und Probleme mit den Flugzeugen zu Flugverspätungen und -stornierungen führen. Da bedarf es schneller und genauer Informationen über alternative Flüge, Umbuchungen oder Entschädigungen für die Passagiere. Vor allem, wenn sie auf den Ausweichflug warten, haben sie Zeit, um nach Entschädigungen zu fragen und darauf zu warten. Wer hier umgehend reagiert, steigt in der Beliebtheitsskala der Kunden sofort nach oben, auch wenn es mal wieder in bisschen länger mit dem Flug dauert.
3. Probleme mit dem Gepäck
Wenn mehr Personen unterwegs sind, bedeutet das automatisch erhöhtes Gepäckaufkommen. Die Wahrscheinlichkeit von mehr Gepäckverlust, -verspätungen oder -beschädigungen steigt entsprechend an. Unterstützt wird das von den oben genannten Flugunregelmäßigkeiten und technischen Problemen am Flughafen. Diese Fälle müssen rasch gelöst werden, um die Zufriedenheit der Passagiere zu gewährleisten. Schnelle Kommunikationswege und Verfolgbarkeit schaffen erste Erleichterungen für das Personal.
4. Kommunikationsvielfalt
Die Wege zu kommunizieren sind so unterschiedlich wie die Flugreisenden selbst. Das heißt, es werden gerne E-Mails, Social Media, Chats, Anrufe und Webforms verwendet. Dabei können Informationen verloren gehen oder gedoppelt werden. Ein Streamlinen der Informationen ist absolut notwendig, um eine konsistente und effektive Kommunikation zu gewährleisten.
5. Personalengpass
Das Kundenserviceteam leidet schon ohne Hochphase an einem Personalmangel. Die erhöhte Reisetätigkeit führt zu weiteren Engpässen, gefördert durch Krankenstand, kurzfristigen Kündigungen oder sprachlichen Hürden mit neuen Kollegen aus anderen Ländern. Automatisierungen im Geschäftsvorgang sind hilfreich, um diese Misere etwas abzumildern.
Mit targenio auch im Sommer einen kühlen Kopf bewahren
Für die Psyche und die Art der Kommunikation ist der hohe Arbeitsanschlag im sommerlichen Kundenservice der Airlines selten ein angenehmes Umfeld. targenio macht es möglich, dass die Agents auch im Sommer entspannt auf ihre Arbeit und mit kühlem Kopf in die Kundenkommunikation gehen. Den Vorteil spüren vor allem die Kunden, die wesentlich zufriedener aus dem Gespräch gehen und bestenfalls zu treuen Fans werden. Fünf ausgewählte Funktionen für die sommerliche Herausforderung haben wir hier aufgelistet:
1. Aufgabenliste mit Funktionen
targenio ermöglicht Mitarbeitern das Anzeigen, Sortieren und Filtern von individuellen oder Gruppenaufgaben. Darüber hinaus integriert die Software Funktionen wie den Bearbeitungsstatus, die Terminberechnung und die Ampelfunktion. Diese Werkzeuge dienen der Priorisierung von Aufgaben und tragen dazu bei, auch während des geschäftigen Sommerreiseverkehrs ein strukturiertes Arbeiten zu erlauben. So können dringende Anliegen effektiv gehandhabt werden, während die Qualität des Kundenservices auf einem hohen Niveau bleibt.
2. 360° Case Management
Mit dem 360° Case Management werden sämtliche relevanten Daten und Funktionen, die zur Bearbeitung eines Vorgangs benötigt werden, in einer einzigen Oberfläche integriert. Dadurch entfällt die Notwendigkeit, in verschiedenen Systemen zu arbeiten. Diese nahtlose Integration erleichtert den Mitarbeitern die effiziente Abwicklung von Vorgängen, insbesondere während hochfrequenter Zeiten, wie der Reisesaison. So können sie zentral auf alle benötigten Informationen zugreifen, ohne zwischen verschiedenen Systemen wechseln zu müssen, was letztendlich Zeit spart und den Passagieren eine kürzere Wartezeit auf eine Antwort bietet.
3. Multicountry Kommunikation
targenio erlaubt nicht nur in den Sommermonaten eine nahtlose internationale Zusammenarbeit zwischen den involvierten Servicemitarbeitern und ihren Kunden. Sowohl Anwender als auch Kunden werden in ihrer jeweiligen Landessprache angesprochen, wobei Zeitzonen, Feier- und Arbeitstage Berücksichtigung finden. Diese Zusammenarbeit wird durch maßgeschneiderte Oberflächen ermöglicht, die individuell auf die Bedürfnisse zugeschnitten sind. Zusätzlich werden Beträge in den jeweiligen Landes- und Konzernwährungen angezeigt. All diese Funktionen unterstützen eine reibungslose grenzüberschreitende Zusammenarbeit, vor allem während der herausfordernden Hochsaison.
4. Intuitive, automatisierte & flüssige Vorgangsbearbeitung Während der hektischen Hochsommersaison werden Kundenservicemitarbeiter durch intuitiv bereitgestellte Informationen, Aufgaben und Workflow-Entscheidungen nahtlos durch verschiedene Abläufe geführt. Zusätzlich kommt hier die Automatisierung ins Spiel. Die Aufgabenpalette reicht von der reibungslosen Erstellung eines Vorgangs mit Kundendaten aus Webformularen, inklusive Datenanreicherung, über die Verarbeitung von Gutscheinen und Zahlungen bis hin zur Abwicklung kompletter Prozesse wie der Bearbeitung von Flugverspätungen von 3 Stunden oder mehr. Diese Herangehensweisen erleichtern und beschleunigen die Bearbeitung von Vorgängen für das Kundenservice-Team erheblich, während gleichzeitig sichergestellt wird, dass Passagiere während dieser geschäftigen Zeit reibungslose und angenehme Kommunikationserlebnisse genießen können.
5. Analytische Einblicke
targenio erleichtert komplexe End-to-End-Prozesse im Kundenservice, wobei die Fähigkeit zur Auswertung der Vorgänge von besonderer Bedeutung ist. Präzise Erkenntnisse ermöglichen die Ableitung zukünftiger Handlungsstrategien. Dies trägt zur Steigerung der Effizienz der Prozesse bei, was wiederum Zeit für individuelle Rückmeldungen an die Passagiere schafft.
Mit targenio entspannt durch den Sommer
Unsere Lösung bietet eine Vielzahl von Funktionen, um Kundenservicemitarbeitern in der Hochsaison zu unterstützen. Von der effizienten Bewältigung hoher Kundenanfragen bis zur nahtlosen Kommunikation über Ländergrenzen hinweg – targenio ermöglicht es, mit Leichtigkeit den Herausforderungen des Sommerreiseverkehrs zu begegnen. Priorisierung von Aufgaben, Integration relevanter Daten und Optimierung von Prozesses – alles in einer zentralen Oberfläche.
Kontaktiere uns gerne, um mehr darüber zu erfahren, wie targenio den Mitarbeitenden die Arbeit in dieser herausfordernden Zeit erleichtern kann.
https://targenio.de/wp-content/uploads/2024/03/marco-lopez-qK6HAkB91Yc-unsplash-scaled-1.jpg17072560Liam Flohryhttps://targenio.de/wp-content/uploads/2024/02/targenio-logo.svgLiam Flohry2023-08-14 06:23:002024-03-25 14:57:27Die fünf größten Herausforderungen für Airlines im Sommer – und wie man ihnen begegnet
Die Reiselust der Deutschen ist trotz Krisen und Inflation ungebrochen. Das ist ein Grund zur Freude in der Reisebranche. Gleichzeitig stellt das neue Herausforderungen dar. Viele Airlines mussten in den letzten Jahren ihre Arbeitnehmerstruktur umbauen und können jetzt oft die wiederkehrenden Anfragen nicht optimal abdecken. Damit die Kundenzufriedenheit dennoch ungebrochen bleibt, kann dem Kundenservice eine kluge Technologie den Rücken frei halten.
Laut der Tourismusstudie des ADAC ist die Reisebereitschaft per Flugzeug zwar noch nicht wieder auf dem Stand vor der Pandemie. Es ist aber sichtbar, dass sich der Bereich erholt und der Trend nach oben geht. Das bedeutet eine wiederkehrend hohe Anfrage in der Reisebranche.
In Kombination mit dem Personalmangel bei den Airlines ist das eine explosive Mischung für die Urlaubszeiten 2023. In den letzten Jahren mussten hunderte Flüge gestrichen, und damit ebenso zahlreiche Stellen, werden. Das bedeutet lange Warteschlangen, verlorenes Gepäck und unzufriedene Flugreisende. Für Entlastung könnte unter anderem Technologie sorgen, wenn sie angemessen eingesetzt wird.
Technologie ist ein Teil der Lösung
Die größte Reisemesse, ITB, hat den Stellenwert der Technologie bereits erkannt. Im Segment Travel Technology der ITB Berlin präsentieren Anbieter in vier Hallen ihre globalen Vertriebssysteme (GDS), Veranstalterdatenbanken, Reservierungssysteme, Reisebürosoftware und Kalkulationsprogramme.
Damit ist klar: Mit Technologie ist nicht nur die gemeint, die man sehen kann. Gerade die unsichtbare Technologie ist wesentlicher Bestandteil von hoher Kundenzufriedenheit. Effiziente technologische Lösungen sind zunehmend ein entscheidender Faktor für erfolgreiche Geschäftsmodelle der Reisebranche. Da spielt auf jeden Fall auch der Customer Service der Airlines eine große Rolle. Wenn es hakt, wollen die Kunden ihr Unbehagen mitteilen können, und ihr Anliegen schnell und zuverlässig bearbeitet wissen.
Targenio AIR bietet Kundenzufriedenheit
targenio AIR ist die Antwort auf eine effiziente Kundenanfrage. Die Software verbindet alle notwendigen Informationen, wodurch der Kundenservice innerhalb kürzester Zeit mit verständlichen Worten eine passende Lösung präsentieren kann. Das bedeutet ein positives Kontakterlebnis bei den Fluggästen, denn sie fühlen sich verstanden und fair behandelt. Kaum ein anderes Gefühl fördert mehr Vertrauen in ein Flugunternehmen – und damit die Bereitschaft wieder mit der Airline zu reisen.
Unsere Software kann ein Schlüssel für den Spagat zwischen Mitarbeitermangel und hohem Reiseaufkommen sein. Deshalb ist morgen unser Leiter Business Development Thomas Baier auf der ITB Berlin unterwegs und kann jederzeit angesprochen werden.
Daneben ist auch Dr. Fried & Partner, ein unabhängiges Partnerunternehmen von uns, vor Ort und kann bereits erste Fragen zu unserer Software beantworten.
https://targenio.de/wp-content/uploads/2024/03/jon-tyson-vVSleEYPSGY-unsplash-scaled-1.jpg17112560Liam Flohryhttps://targenio.de/wp-content/uploads/2024/02/targenio-logo.svgLiam Flohry2023-03-06 14:05:032024-03-08 11:13:04Fliegen ist eine Frage der Technologie – auch auf der ITB Berlin
Seit 20 Jahren befassen wir uns mit der Idee, dass Software Kundenwünsche verstehen können soll. Unsere ersten Versuche, das Kategorisieren von Kundenanliegen mit Hilfe von künstlicher Intelligenz zu automatisieren, waren ernüchternd. Die Klassifizierungsfähigkeiten der verfügbaren Algorithmen waren ungenügend. Und die benötigten Rechenressourcen zu hoch, um Künstliche Intelligenz (KI) produktiv einzusetzen.
Mit der Weiterentwicklung der Technologie, und der heute zur Verfügung stehenden Rechenpower, war es an der Zeit, diesen Versuch zu wiederholen. Dabei probierten wir aus, ob mit Hilfe von Machine Learning (ML) die Aufgabe der Zuordnung von unstrukturierten Kundentexten zu Kategorien automatisiert werden kann.
In unserem ersten Artikel zu KI und ML haben wir die allgemeine Entwicklung und Einsatzmöglichkeiten dargestellt. In diesem Beitrag beschreiben wir unsere aktuellen Ansätze, wie die Aufgabe „Kategorisieren von Kundenfeedback“ durch den Computer unterstützt, beziehungsweise übernommen werden kann. Bevor wir allerdings auf unsere konkreten Experimente eingehen, möchten wir vorab darstellen, welche Bedeutung das Kategorisieren von Sachverhalten im Kontext „Kundenservice“ hat.
Warum Kategorienbildung?
In jedem Augenblick, in jeder Konfrontation, suchen wir instinktiv nach Wegen, unsere Umwelt zu strukturieren, zu durchschauen, oder zumindest einen Überblick über sie zu gewinnen. Hierbei helfen uns Modelle die Komplexität zu reduzieren. Diese Modelle blenden einen Teil der Wirklichkeit aus und erlauben uns, dass wir uns auf das Wesentliche konzentrieren. Erst mit deren Hilfe sind wir in der Lage, in einer chaotischen Umwelt sinnvolle Entscheidungen zu treffen.
Das fundamentalste Modell, zu dem das menschliche Denken fähig ist, ist dabei die Kategorisierung, oder Kategorienbildung, bei der Objekte und Situationen in Gruppen, Untergruppen oder Begriffsklassen eingeteilt werden. Im Gegensatz zum bloßen Speichern von einzelnen Erfahrungsinhalten, geht dem Kategorisieren ein Denkprozess voraus, der die Ähnlichkeit von Objekten und Situationen untersucht und bewertet. Durch die Kategorisierungsfähigkeit unserer Gehirne erreichen wir eine größere Verhaltensflexibilität bei gleichzeitiger zeitökonomischer Verbesserung des Entscheidungsprozesses.
Was daraus für dein Unternehmen folgt?
Die Denkmodelle, die – bewusst oder unbewusst – in deinem Unternehmen vorherrschen, befähigen oder begrenzen die Fähigkeit, schnell, zuverlässig und wiederholbare Entscheidungen zu treffen. Vor diesem Hintergrund ist das zuverlässige Kategorisieren essentiell, damit du optimale Entscheidungen in deinem Unternehmen triffst. Mit diesem Wissen ergibt sich die herausfordernde Aufgabe, ein Kategoriensystem für dein Unternehmen mit Bedacht und Weitsicht zu entwickeln und anzuwenden.
Die Notwendigkeit eines solchen umfassenden Kategoriensystems ergibt sich insbesondere im Kundenservice. Hier laufen in besonderem Maße unstrukturierte Informationen aus einer Vielzahl von unterschiedlichen Quellen zusammen, die verarbeitet werden müssen. Ein „energiesparendes“ Entscheiden ist nur möglich, wenn das Zuordnen zu Kategorien schnell, einfach und zuverlässig erfolgt.
Anforderungen an ein Kategorisierungssystem
An das im Kundenservice eingesetzte Kategoriensystem ergeben sich damit folgende Anforderungen: Das Kategoriensystem, also das Set an Merkmalen, muss benennbar und minimal hinreichend sein. Es sollte also möglichst wenige Merkmale enthalten. Und dennoch ausreichend umfangreich sein, um alle Sachverhalte, mit denen der Kundenservice konfrontiert wird, zu beschreiben.
Das Kategoriensystem muss sicherstellen, dass die relevanten Handlungsfelder ausreichend repräsentiert sind, um eine hinreichende Informationsgrundlage für Entscheidungen der Geschäftsleitung zu ermöglichen. Am Beispiel einer Airline bedeutet dies konkret, dass der Kundenservice zu den „großen“ Themen auskunftsfähig sein muss:
Wie viele Fluggäste haben sich bezüglich einer Flugverspätung beschwert?
Wie viele Gäste haben einen Kofferschaden erlitten?
Wie viele Anfragen zu Umbuchungen mussten bearbeitet werden?
Darüber hinaus muss es das Kategoriensystem ebenfalls ermöglichen, „kleinere“ Themen angemessen abzubilden. Bei diesen Kategorien geht es weniger darum, die reine Anzahl der betroffenen Kunden und Vorgänge zu ermitteln. Vielmehr ist es notwendig, aus der Menge der Vorgänge ohne großen Aufwand diejenigen zu identifizieren, an denen einzelne Stakeholder ein besonderes Interesse haben.
Gesetzliche Vorschriften führen zu einem Kategoriensystem
Schließlich muss es das Kategoriensystem ebenso ermöglichen, die Vorgänge zu kennzeichnen. Denn Unternehmen sind aufgrund gesetzlicher Vorschriften verpflichtet, gesondert Auskunft zu geben. So fordert die kanadische Luftaufsichtsbehörde, dass Airlines Auskunft über die Anzahl von Beschwerden mit Musikinstrumenten geben. Hintergrund für diese kuriose Anforderung ist vermutlich der Vorfall, bei dem der kanadische Musikers David Carroll die Zerstörung seiner Gitarre während einer Flugreise mit United Airlines selbst mit ansehen musste.
Auch wenn das Kategorisieren primär den Informationsinteressen der Entscheidungsträger im Unternehmen dient, ist ein durchdachtes und gut strukturiertes Kategoriensystem ebenfalls für den Mitarbeiter im Kundenservicehilfreich. Dieser hat die Aufgabe des Kategorisierens von Vorgängen. Beim Reflektieren über die richtige Zuordnung eines Vorgangs zu einer Kategorie, verschafft sich der Mitarbeiter für sich selbst Klarheit und Verständnis über den Vorgang. Dieses „Durchdenken“ erleichtert dem Mitarbeiter die Bearbeitung des Vorgangs und unterstützt das Treffen von angemessenen Entscheidungen. Zusätzlich kann der Mitarbeiter nach Feststellen der Kategorie in der Vorgangsbearbeitung durch targenio entlastet werden. targenio weist den Mitarbeiter auf ähnliche Bearbeitungen hin, zeigt relevante Informationen zur ausgewählten Kategorie an oder schlägt passende Textbausteine für das Beantworten eines Vorgangs vor.
Kategoriensystem im Kundenservice
Der Wert eines Kategoriensystems ergibt sich aus der Nützlichkeit der Informationen, die mit Hilfe der Kategorien codiert werden. Allein hieraus ist sichtbar, dass es keine allgemeingültigen Aussagen für den Aufbau eines Kategoriensystems geben kann. Allerdings haben wir durch die jahrelange Beschäftigung mit dem Thema „Kundenservice“ Erfahrungen gesammelt, wie ein Kategoriensystem aufgebaut und entwickelt werden sollte.
„Ex ante“ oder „Ex post“
Zunächst stellt sich die Frage, was und wann kategorisiert werden soll. Grob vereinfacht finden wir folgenden typischen Ablauf im Kundenservice:
Input: Der Kunde richtet sein Anliegen an den Kundenservice per E-Mail, über ein Kontaktformular oder per Telefon.
Processing: Ein Kundenservicemitarbeiter versucht das Anliegen des Kunden zu verstehen, prüft und validiert die Angaben des Kunden, wägt ab und trifft dann eine Entscheidung.
Output: Anschließend führt der Mitarbeiter die getroffene Entscheidung aus, wählt beispielsweise eine Lösung und informiert den Kunden.
Üblicherweise verbessert sich Art, Qualität und Umfang der Informationen, je weiter eine Bearbeitung voranschreitet. Hat der Mitarbeiter die Bearbeitung abgeschlossen, die Entscheidungen vollzogen, die vom Kunden akzeptiert wurde, sind die bis dahin fluiden Informationen fix. Daraus könnte abgeleitet werden, dass eine Kategorisierung erst nach der Bearbeitung – also ex post – erfolgen sollte.
Tatsächlich ist es aber so, dass am Beginn einer Bearbeitung eine Kategorisierung auf Basis der vom Kunden übermittelten Informationen erfolgt. Das frühe Kategorisieren wird sofort verständlich, wenn man bedenkt, welchen Informationsbeitrag der Kundenservice innerhalb eines Unternehmens leisten kann. Der Kundenservice macht die Stimme des Kunden für das Unternehmen sichtbar.
Zur Verdeutlichung ein anschauliches Beispiel aus der Airline Branche
Ob ein Flugzeug verspätet ist, und den Passagieren Ansprüche auf Ausgleichszahlungen nach Fluggastrechte-Verordnung zustehen, weiß eine Airline meist schon bevor das Flugzeug überhaupt gelandet ist. Diese Informationen ergeben sich aus den operativen Systemen, wie einem Fluginformationssystem. Die Information, wie die Verspätung von den Passagieren wahrgenommen wird, und ihre Reaktionen darauf, besitzt der Kundenservice exklusiv.
Hinzu kommt, dass der Kundenservice mit einer „frühen“ Kategorisierung den Vorgang versachlichen kann. Die Kategorien subtrahieren die Emotionen aus der Kundenäußerung, so dass eine faktenbasierte, rationale Entscheidung möglich wird. Zusätzlich unterstützt die IT die Fallbearbeitung leichter nach dem Zuordnen der Kundenartikulation zu Kategorien.
Ex ante wird oft durchgeführt
Aufgrund dieser Überlegungen erfolgt das Kategorisieren regelmäßig ex ante – also am Anfang der Fallbearbeitung. Gegenstand der Kategorisierung ist dabei die Äußerung des Kunden.
An dieser Stelle soll nicht unerwähnt bleiben, dass häufig auch am Ende der Bearbeitung noch Kategorisierungen vorgenommen werden. Hier halten die Bearbeiter dann fest, ob das Anliegen des Kunden berechtigt war, gelöst werden konnte oder welche Organisationseinheit als Problemverantwortlicher im identifiziert werden konnte. Diese Informationen werden für Qualitätssicherungen oder Root cause analysis benötigt. Das Kategorisieren von Ursachen bleibt einem eigenen Beitrag vorbehalten.
Entwicklung eines Kategoriensystems für den Kundenservice
Nachdem nun feststeht, welche Informationen überhaupt kategorisiert werden sollen, stellt sich die Frage, wie ein sinnvolles und nützliches Kategoriensystem entwickelt werden kann. In der Theorie gibt es induktive und deduktive Methoden zur Kategorienbildung – in der Praxis zeigt sich jedoch, dass keine der Methoden und Ablaufmodelle streng zur Anwendung kommen. Dieses undogmatische Vorgehen ist nachvollziehbar, da jedes Kategoriensystem im Unternehmen das Ergebnis von Verhandlungen ist, bei dem widerstreitende Interessen ausgeglichen werden müssen.
Zum einem erfordern die oben skizzierten Interessen („große“ und „kleine“ Themen, Erfüllung gesetzlicher Anforderung), dass Informationen mit unterschiedlicher Granularität zu Kategorien verdichtet und zusammengefasst werden. Zum anderen bewerten die verschiedenen Stakeholder im Unternehmen die Nützlichkeit der Aggregationen unterschiedlich.
Ein Beispiel: Wenn es für das Bearbeiten eines Kundenanliegens im Kundenservice keinen Unterschied macht, ob der Kunde das Produkt A oder B gekauft hat – weil die Bearbeitung bei beiden Produkten identisch abläuft, so macht es für die Produktmanager von A und B doch einen erheblichen Unterschied, ob „ihr“ Produkt Gegenstand eines Kundenanliegens ist.
Das System muss schnell, einfach und zuverlässig sein
Hinzu kommen weitere Aspekte: Der Kundenservice benötigt ein Kategoriensystem, das schnell, einfach und zuverlässig das Kategorisieren der verschiedenen Kundenanliegen erlaubt. Da die Kategorien aus der Kundenartikulation abgeleitet werden müssen, ist es einfacher ein System zu nutzen, das aus Kundenperspektive heraus aufgebaut ist. Ein anderes Interesse hat unter Umständen das Management, das die Kundenanliegen aus Sicht der Aufbau- oder Ablauforganisation kategorisiert haben möchte.
Ein Kategoriensystem im Kundenservice ist ein Kompromiss: Ein Kategoriensystem, dass die „Order to Cash“ Kette abbildet oder sich entlang einer Customer Journey orientiert, hat sich nach unserer Wahrnehmung bewährt. Ein solches System lässt sich leicht erlernen, was wichtig für den Kundenservice ist. Außerdem findet sich jeder Stakeholder ausreichend repräsentiert.
Daneben hat sich bewährt, die Sicht der Kunden mit der Wertschöpfungskette des Unternehmens zu „kreuzen“. So deckt sich die Kundenperspektive mit der Unternehmenssicht.
Struktur eines Kategoriensystems im Kundenservice
Für targenio haben wir für das Kategorisieren von Kundenanliegen eine Methodik entwickelt, die den oben genannten Aspekten ausreichend Rechnung trägt und sich in der Praxis bewährt hat. Insbesondere gilt das für das Beschwerde- und Reklamationsmanagement. Beim Kategorisieren sehen wir einen mehrstufigen Baum vor, der in vier Entitäten gruppiert ist:
Art des Kundenanliegens
Ort des Problemauftritts
Bezugsbereich
Kundenartikulation
Jede Entität kann wiederum mehrere Ebenen haben, damit auch umfangreiche Kategoriensysteme abgebildet werden können. „Art des Kundenanliegens“, „Bezugsbereich“ und „Kundenartikulation“ sowie die einzelnen Ebenen sind miteinander verkettet. Von einem Blattelement ausgehend, können alle vorhergehenden Knoten rekursiv ermittelt werden. targenio macht es möglich, eine Kundenartikulation mehreren Kategorien zuzuordnen. Dies vereinfacht die Pflege und Handhabung des Kategoriensystems. Es wird zudem berücksichtigt, dass Kunden in ihrer Nachricht mehrere Themen an den Kundenservice adressieren können.
Vier Ebenen sind in den jeweiligen Entitäten vorhanden
Bei „Art des Kundenanliegens“ wird der Wunsch, das Ersuchen oder der Antrag des Kunden erfasst. Im Beschwerdemanagement sind dies die klassischen Anliegenarten zu finden: „Beschwerde“, „Wiederholungsbeschwerde“ und „Folgebeschwerde“. In anderem Kontext können dies beispielsweise die Anliegen „Anfrage“, „Bestellung“ oder „Lob“ sein.
Beim „Ort des Problemauftritts“ wählt der targenio Anwender die Organisationseinheit aus, die vom Anliegen des Kunden betroffen ist. Diese Entität ist optional, empfiehlt sich aber bei Flächenorganisationen beziehungsweise Dienstleistungsunternehmen, wenn Zuordnungen von Anliegen zu Kunden-Touchpoints relevant sind. Alternativ kann an dieser Stelle ein konkretes Produkt oder eine Dienstleistung angegeben werden.
Der „Bezugsbereich“ repräsentiert die Wertkette des Unternehmens und kennzeichnet die konkrete Aktivität, auf die sich das Kundenanliegen bezieht. Gerade hier empfiehlt sich eine Nachbildung der Tätigkeiten in der Reihenfolge „Order to Cash“, da dies die Verortung im Kundenservice erheblich vereinfacht.
Nach dem „Bezugsbereich“ ist die Kategorisierung mit der Erfassung der „Kundenartikulation“ abgeschlossen. Damit ist das Kondensat des Kundenfeedbacks in konkreten Kategorien dokumentiert.
Kategorisierung eines Fluges mit targenio bei einer Airline
Diese Struktur erlaubt eine schnelle und einfache Zuordnung von Kundenfeedback und berücksichtigt die Auswertungs- und Informationsinteressen der verschiedenen Stakeholder im Unternehmen.
Anwendung des Kategoriensystems
Nachdem das Kategoriensystem entwickelt worden ist, bleibt die herausfordernde Aufgabe, das Kategoriensystem auch in der täglichen Praxis anzuwenden. Selbst wenn Kunden ihr Anliegen unterschiedlich artikulieren, sollen Sachverhalte durch die Mitarbeiter im Kundenservice einheitlich und neutral kategorisiert werden. Hierbei helfen Ankerbeispiele und ausführliche Kodierregeln, die zu einem Kodierleitfaden zusammengefasst werden. Mit Hilfe von Stichprobenauswertungen und qualitativen Analysen muss die Genauigkeit beziehungsweise Verlässlichkeit der Kategorisierung durch die Mitarbeiter im Kundenservice kontinuierlich überwacht werden. Durch Schulungen und Anpassungen des Kategoriensystems sind ständige Nachjustierungen notwendig.
Um den Kundenservice beim Kategorisieren von Kundensachverhalten zu unterstützen, und gleichzeitig weitere Automatisierungspotentiale zu realisieren, beschäftigen wir uns intensiv mit Machine Learning. Die Überlegungen dabei sind, dass die artikulierten Kundenanliegen mit Hilfe von künstlicher Intelligenz analysiert und mittels trainierter Algorithmen dem definierten Kategoriensystem zugeordnet werden.
Forschungsfrage und Versuchsaufbau
Damit wir beim Experimentieren mit Machine Learning fokussiert bleiben, und aussagekräftige Ergebnisse erarbeiten, haben wir zunächst eine konkrete Forschungsfrage formuliert. Diese diente uns während unseres Forschungsprojekts als Leitfaden, und als Gradmesser für Erfolg und Misserfolg.
Folgende Forschungsfrage haben wir formuliert: In welcher Qualität lassen sich Kundenschreiben mithilfe von überwachtem maschinellem Lernen kategorisieren?
Ausgangspunkt unseres Versuchsaufbaus sind Schreiben von Fluggästen, die an den Kundenservice einer unserer Airline-Kunden gerichtet worden sind. Diese Texte geben Kunden über ein Kontaktformular im Internet ein. Zusätzlich wählt der Kunde aus einer Liste aus, welches Anliegen er hat. Zum Beispiel „Flugstornierung“ oder „Überbuchung / Nichtbeförderung“. Den Text und die getroffene Auswahl übernimmt unsere Kundenserviceanwendung targenio und an leitet sie einem zuständigen Sachbearbeiter weiter. Ein Mitarbeiter liest den Sachverhalt und kategorisiert das Anliegen im Kategoriensystem von targenio. Das Kategoriensystem hat in Summe circa 230 Ausprägungen, bestehend aus Anliegenart, zwei Ebenen Bezugsbereich und zwei Ebenen Artikulation.
Die KI lernt, Gesetzmäßigkeiten nachzubilden
Damit liegen also zwei aufeinander bezogene Entitäten vor: Zum einen der unstrukturierte Kundentext, in dem der Kunden sein Anliegen artikuliert hat, zum anderen die durch einen Sachbearbeiter vorgenommene Klassifizierung dieses Textes. Der Sachbearbeiter hat aufgrund seiner Erfahrungen und seines Expertenwissens den unstrukturierten Text in ein strukturiertes System überführt.
Auf Aufgabenstellungen dieser Art wird bei KI-Systemen üblicherweise überwachtes Maschinelles Lernen angewandt. Durch das Trainieren der KI „lernt“ die Maschine, die Gesetzmäßigkeiten nachzubilden und das Expertenwissen aufzubauen. Damit wendet die KI dieses Wissen auch auf unbekannte Texte an und findet eine passende Kategorisierung.
Beim Machine Learning spricht man dabei von Features, hier: Kundentexte, und Labels, in dem Fall der Kategorisierung. Dem Machine Learning Algorithmus werden beim Training Paare aus Features and Labels “gezeigt”. Dadurch erlernt der Algorithmus das zugrunde liegende Mapping. Er lernt also die Kategorien, die in den Texten stecken, zu generalisieren und nutzbar zu machen. Dieses generalisierte Mapping von Feature auf Label ist dann die eigentliche KI. Die Menge an Feature-Label Paaren, die einem ML Algorithmus zum Lernen zur Verfügung gestellt werden, werden Lerndaten genannt. Nach dem Training kann die KI auf neue, ungesehene Features angewandt werden, bei denen sie das passende Label ermittelt.
Lerndaten bereitstellen
Das Bereitstellen von Lerndaten für das ML Modell durchlief mehrere Arbeitsschritte: Zunächst haben wir festgelegt, mit welchen Daten wir den Algorithmus trainieren wollen. Um bereits in den Lerndaten möglichst wenig „Rauschen“ zu haben, wurden Kundentexte, die von Fluggästen in deutscher Sprache verfasst worden sind, extrahiert. Und von Sachbearbeitern lediglich mit einer Kategorie klassifiziert worden sind, sprich monothematische Kundenanliegen.
Nach Prüfung, ob für verschiedene Versuchsreihen eine ausreichend große Anzahl von Daten vorhanden ist, haben wir die Daten in der Datenbank selektiert, anonymisiert und um schützenswerte Kunden- und Mitarbeiterdaten bereinigt. Ebenso haben wir interne Bearbeitungsvermerke gelöscht, um für das Training möglichst unverfälschte Daten zu erhalten. Anschließend exportierten wir die Daten aus der Datenbank im CSV-Format und stellten sie an einem sicheren Speicherort für das Training der ML-Modelle bereit.
Das Kundenfeedback vorverarbeiten
Computer und Algorithmen arbeiten grundsätzlich mit Zahlen. Bevor die Kundenschreiben von der KI verarbeitet werden können, müssen die Texte vor-verarbeitet und in Vektoren umgewandelt werden (“preprocessing). Ein Vektor kann vereinfacht als eine Liste fixer Länge, die Nummern enthält, beschrieben werden. Beispielsweise lassen sich Ortsangaben als zweidimensionaler Vektor, bestehend aus Längen- und Breitengrad in einem Koordinatensystem, definieren. Ein Datenpunkt (ein Sample) fürs Machine Learning ist also ein Vektor, der den Datenpunkt mithilfe numerischer Werte möglichst gut beschreibt.
Für das Umwandeln von Texten in Vektoren gibt es verschiedene Verfahren, die man miteinander kombiniert: Eine Möglichkeit besteht darin, die Häufigkeit jedes Wortes des gesamten Vokabulars im umzuwandelnden Text zu zählen. Zusätzlich lassen sich die Worte noch nach ihrer umgekehrten, relativen Häufigkeit gewichten. Bestimmte und unbestimmte Artikel, Konjunktionen und häufig gebrauchte Präpositionen (sog. Stopwords), die in vielen Texten vorkommen und wenig Relevanz für das Textverständnis haben, gewichet das System dabei schwach, während es seltenerer Begriffe, wie Fachbegriffe, höher gewichtet. Diese Gewichtung erleichtert dem Machine Learning Algorithmus, die wirklich relevanten Charakteristiken des Textes zu erkennen und zu verwenden. Dieses Verfahren nennt man TF-IDF (term frequency – inverse document frequency). Zusätzlich beschränkt das System verbleibende Worte auf ihren Wortstamm (Stemming). Durch das Einschränken des Vokabulars wird das ML-Modell weniger von sogenanntem Noise abgelenkt, und “kann sich auf das wirklich wichtige konzentrieren“.
CountVectorizer: Ein Text wird in eine Vektor durch Zählen der enthaltenen Worte in einen Vektor umgewandelt.
Es kommt nicht nur auf das Zählen an
Diese Verfahren sind robust und liefern regelmäßig brauchbare Ergebnisse. Allerdings geht durch das einfache Zählen der Wörter die Reihenfolge der Wörter, die Grammatik und der Kontext verloren. Für anspruchsvolle Natural Language Processing Aufgaben, wie Übersetzung oder Question-Answering, kommen andere Methoden zur Anwendung. Bei modernen Deep Learning Modellen, die auf der Transformers-Architektur basieren, kommen sogenannte Tokenizer zum Einsatz. Dabei wird jedem möglichen Wort im Vokabular ein fester Ganzzahlwert (das Token) zugeordnet. Diese Modelle verarbeiten den Eingabetext in seiner Ursprungsform, nur dass Wort-Teile durch ihre jeweiligen Tokens ersetzt sind. Auf diese Weise bleibt die Reihenfolge bewahrt und der Sinn erhalten. Modelle, die solche Sätze aus Tokens verarbeiten und verstehen können, müssen ziemlich groß und leistungsfähig sein. Sie benötigen erhebliche Rechenleistungen sowie eine große Mengen an Lern- und Trainingsdaten.
Bei der Wahl des passenden Vektorizers und dem eigentlichen Machine Learning Modell muss zwischen Kosten und Nutzen abgewogen werden. Bei unserem Forschungsvorhaben, dem Mapping von Texten auf Kategorien – eine Aufgabe, die zu den einfacheren NLP-Task gezählt werden kann –, haben wir uns entschieden, das Vektorisieren durch Zählen in Kombination mit einem Nicht-Deep-Learning ML-Algorithmus zu verproben.
Auswahl eines ML Algorithmus
Sind die Daten exportiert, bereinigt und vektorisiert kann man einen geeigneten ML Algorithmus darauf trainieren. Die Auswahl eines geeigneten ML Algorithmus erfordert Erfahrung. Diese sammelt Erfahrungen man durch Ausprobieren. Oder man nutzt hierzu Entscheidungshilfen, mit denen eine Vorauswahl getroffen werden kann. Mit zahlreichen Programmier-Bibliotheken, zum Beispiel diese Erweiterung für scikit-learn, lässt sich der Auswahl-Prozess auch automatisieren.
So nützlich solche automatisierten Auswahlverfahren sind. Es sollte nicht übersehen werden, dass möglicherweise Lernerfahrungen über die Daten und das Verhalten der einzelnen Algorithmen verloren gehen können. Erst beim mühevollen Ausprobieren der verschiedenen Algorithmen sammelt man die Erfahrung, welcher Algorithmus für die Aufgabenstellung und die eigenen Daten besser geeignet ist.
Mehrere ML Modelle werden trainiert, die den Durchschnitt bilden
Für das Kategorisieren von Texten haben sich unter anderem Naive Bayes und Support-Vector-bewährt. Oftmals werden auch sogenannte Ensembles verwendet. Dabei trainiert man mehrere unterschiedliche ML Modelle und bildet den Durchschnitt über deren einzelne Ausgaben, um die Ausgabe des Ensembles zu erhalten. Dadurch werden die Vorhersagen robuster.
Grundsätzlich gilt: keine noch so gute Wahl des Modells kann schlechte Datenqualität kompensieren. Umgekehrt können bei guter Datenqualität mit mehreren verschiedenen ML Algorithmen brauchbare Ergebnisse erzielt werden können. Das zeigen auch die Versuche.
Wir haben uns nach mehreren Iterationen entschieden, unser Forschungsprojekt mit (lineare) Support-Vector-Machine fortzuführen. Diese performt gut und ist gleichzeitig noch relativ effizient. Für das Trainieren der Modelle fiel unsere Wahl auf scikit-learn. Das ist eine open-source Programmierbibliothek für die Programmiersprache Python. Python gilt als der Standard unter ML Entwicklern. Es bietet eine sehr große und gute Palette an Frameworks und Toolkits für Maschinelles Lernen.
Das Training der Support Vector Machine
Support-Vector-Machines erlernen das Kategorisieren (im ML Kontext würde man sagen zu Klassifizieren), indem sie die optimale “Trennung” zwischen Datenpunkten (dargestellt als Vektoren) verschiedener Kategorien in den Trainingsdaten errechnen. Diese Trennung kann nach dem Training benutzt werden, um neue, zuvor ungesehene Datenpunkte einzuordnen.
Wir haben für jede der Kategorienebenen (Art des Anliegens, Bezugsbereich und Artikulation) ein eigenes Modell trainiert, also insgesamt fünf Stück. Damit haben wir bessere Ergebnisse erzielt als mit unserem zunächst gewählten Ansatz, ein Modell für alle Ebenen zu bauen.
Ergebnisse quantitativ auswerten
Um die Qualität der fünf Modelle bewerten zu können, haben wir ausführliche Tests gemacht, wobei das erste Testszenario aus circa 100.000 Datensätzen bestand. Dazu haben wir 30% der Daten beim Trainieren zunächst zurückgehalten. Als das Training mit den übrigen Datensätzen, ca. 70%, beendet war, konnten wir diese zum Testen heranziehen. Durch dieses Vorgehen konnten wir überprüft, ob das ML Modell wirklich die den Trainingsdaten zugrundeliegenden Konzepte erlernt hat. Und es nicht nur die Trainingsdaten auswendig gelernt hat. Dieser Effekt würde als “Overfitting” bezeichnet.
Die Tabelle zeigt anhand eines Ausschnitts beispielhaft wie die Auswertung der Testdaten vereinfacht aussehen.
Jede Zeile gehört zu einer Kategorie. Die Spalte Support enthält die Anzahl der Testdaten zur jeweiligen Kategorie. Die unterste Zeile gibt die Metriken für die Kategorien gemeinsam an. Diese exemplarische Auswertung bezieht sich auf das Modell, das wir für die Kategorisierungsebene Bezugsbereich 1 trainiert haben.
Mit den Metriken Precision und Recall lässt sich die Qualität von vorhergesagten Kategorisierungen quantifizieren. Precision ist ein Maß für die Genauigkeit und ist als die relative Häufigkeit definiert, dass eine Klasse richtig ist, wenn sie vorhergesagt wird. Recall hingegen ist die Trefferquote. Sie gibt die relative Häufigkeit an, dass ein Klasse auch als solche vorhergesagt wird. Der F1-Score ist eine Art Kombination von Precision und Recall. Gemeinsam geben diese Metriken soliden Aufschluss über die Performance bei Klassifikatoren.
Zudem sind beispielsweise 81% der Texte, die die KI mit Label “Airport“ versehen hat, auch tatsächlich (also vom Sachbearbeiter klassifiziert) “Airport”. Recall von 82% bei “Airport” bedeutet, dass 82% aller Texte, die tatsächlich “Airport” sind, die KI auch als solche erkannt hat.
Nachdem wir beobachtet haben, dass die Modelle gute Ergebnisse liefern, haben wir die Menge der Lerndaten vervierfacht und die Schritte von oben wiederholt. Dadurch wurden die Modelle besser und vor allem robuster gegenüber Sonderfällen.
Leistungsfähigkeit der KI nachvollziehbar machen
Für Menschen, die sich nicht täglich mit den Themen Künstliche Intelligenz und Automatisierung beschäftigen, ist Machine Learning „Voodoo“. Damit wir Vertrauen in die Leistungsfähigkeit des ML Systems aufbauen und die Ergebnisse nachvollziehbar und persönlich testbar machen, haben wir ein kleines Programm erstellt, mit dem
der Text des Kunden und die erfasste Kategorisierung eingefügt,
das ML Modell mit den Daten ausgeführt,
die Kategorisierung durch das Modell und vom Sachbearbeiter ausgegeben und
das Ergebnis kommentiert
wird.
Ein Programm zeigt den Ablauf
Zu Beginn kopiert das Programm den Kundentext und die vom Sachbearbeiter in targenio erfasste Kategorisierung in das Feld „Sachverhalt“. Der ML Algorithmus wendet dann sein antrainiertes Wissen an. Das wird in der linken Spalte die Kategorisierung des ML angezeigt. In der rechten Spalte ist die vom Sachbearbeiter erfasste Kategorisierung gegenübergestellt, so ist ein unmittelbarer Vergleich zwischen Mensch und Maschine möglich:
Dieses Video zeigt einen Ausschnitt aus unserem Frontend zum Erkennen von Kundenanliegen aus Text, mit einem Beispiel, in dem die Vorhersage und die menschliche Kategorisierung identisch sind.
Da wir dieses Programm auch für unsere qualitativen Tests verwendet haben, ist zusätzlich zu jedem Testlauf der Name des Testers, das Testergebnis und eine Referenz auf den Original-Vorgangsdatensatz dokumentiert.
Das komplette Testsetup ist in folgendem Architekturbild dargestellt:
Die Architektur des KI Systems
Nach einigen Testläufen hat sich für uns folgendes Bild herauskristallisiert: Das von uns trainierte Modell kategorisiert einen Großteil der Kundentexte genauso, wie die Sachbearbeiter im Kundenservice. Bei einem geringen Anteil der Testdatensätze ermittelte die KI eine fehlerhafte Kategorie. Und bei einem weiteren Großteil der getesteten Sachverhalte wich das Ergebnis der KI zwar von der Kategorisierung des Kundenservicemitarbeiters ab, war aber fachlich nicht falsch, sondern nur anders.
Als Ursachen für fehlerhaft klassifizierte Sachverhalte haben wir eine zu geringe Anzahl an Testfällen in den Lerndaten und redundante Einträge im Kategoriensystem identifiziert; daraus haben wir zwei Optimierungsschritte abgeleitet: Signifikante Erhöhung der Lerndaten und Priorisierung der Ergebnisse anhand der Struktur des Kategorienbaums in targenio.
ML Anwendung optimieren
Wie oben beschrieben, hatten wir uns entschieden, für jede Ebene der Kategorisierung ein eigenes Modell zu trainieren. Dadurch konnte der Algorithmus Kombinationen von Kategorien erlernen, die in der Baumstruktur des Kategoriensystems von targenio gar nicht auswählbar sind.
Um dieses Problem zu heilen, haben wir uns eine Funktion der Modelle zunutze gemacht, dass nämlich die Modelle eine Wahrscheinlichkeit für alle möglichen Kategorien der jeweiligen Kategorienebene ausgeben. Diese Wahrscheinlichkeitsangaben haben wir einfließen lassen, indem wir für Gesamtvorhersagen diejenige Kategorisierung wählen, die größtmögliche Gesamtwahrscheinlichkeit (das Produkt der fünf einzelnen Wahrscheinlichkeiten) hat und gleichzeitig mit dem Kategorienbaum konsistent ist. Dieser Abgleich der Vorhersagen mit dem Kategoriensystem machte die KI als Ganzes robuster.
Nach dem Abgleich mit dem targenio Kategorienbaum und der Ausweitung der Lerndaten haben wir die Optimierung des Modells realisiert. Das führte dazu, dass die KI weit über 80% der Kundentexte richtig (in Sinne: entspricht der vom Sachbearbeiter vorgenommenen Kategorisierung) klassifiziert hat.
Beantwortung der Forschungsfrage, Lessons learned und Perspektive
Unser Projekt hat gezeigt, dass wir mit der heute verfügbaren Machine Learning Technologie unstrukturierte Kundentexte auf ein umfangreiches Kategoriensystem mappen können. Hierbei stimmen die Ergebnisse der KI zu mehr als 80 % mit den von Sachbearbeitern erfassten Kategorisierung überein.
Sind > 80 % Übereinstimmung ausreichend, um ML produktiv im Kundenservice einzusetzen und die Mitarbeiter bei der Bearbeitung von Kundenanliegen zu entlasten? Ist die Qualität der ML Algorithmen also hoch genug?
Nach unserer Meinung ein eindeutiges JA!
Dieses “JA” stützt sich auf Überlegungen und Erkenntnissen, die wir im Laufe des Projekts und mit der intensiven Beschäftigung der Daten gesammelt haben:
Der verwendete Kategorienbaum ist in sich nicht eindeutig und widerspruchsfrei. Zudem ist er nicht ausreichend ausgewogen und “überbetont” bestimmte Sachverhalte bei gleichzeitigem Negligieren ganzer Bereiche.
Die Anwendung des Kategorienbaums erfolgt durch eine große Anzahl von Sachbearbeitern mit unterschiedlichen Skills und Erfahrungen. Von daher ist nicht anzunehmen, dass ein- und derselbe Kundentext durch verschiedene Mitarbeiter identisch klassifiziert wird.
Selbst bei gleich hoher Qualifikation und Motivation der Mitarbeiter verbleiben Zweifelsfälle, die legitimerweise unterschiedlich interpretiert und ausgelegt werden können.
Stellt man diese Überlegungen der aktuell ermittelten Übereinstimmung von 80 % gegenüber, dann ergibt sich ein akzeptables Niveau, zumal die KI Texte neutral, reproduzierbar und in gleichförmig klassifiziert.
Welche sonstigen Erkenntnisse haben wir durch unser Projekt gewonnen?
Wie zu erwarten, bestimmt die Menge und Qualität der Daten die Leistungsfähigkeit der KI. So konnten wir durch eine Erhöhung der Lerndaten von 100.000 auf 400.000 Datensätze eine signifikante Verbesserung der Ergebnisse erzielen. Die eingesetzten, frei verfügbaren open source Modelle erlauben einen wirtschaftlichen Einsatz von künstlicher Intelligenz für Aufgabenstellungen im Kundenservice. Durch geeignete Maßnahmen können die Ansprüche des Datenschutzes eingehalten werden.
Wie sind nun die Perspektiven?
Künstliche Intelligenz und Machine Learning sind bereit für den produktiven Einsatz. Die Treffsicherheit unseres ML Modells ist ausreichend hoch, um damit die nächste Ebene der Automatisierung zu erreichen und neue Use Cases umzusetzen. Welche das sind, zeigen wir in unserem nächsten Artikel dieser Serie auf.
Takeaway
Das Entwickeln eines Kategoriensystems, das zugleich nützlich und einfach ist, ist eine herausfordernde Aufgabe.
Unsere Versuche zeigen, dass KI-Algorithmen heute sehr gut und treffsicher unstrukturierte Texte zu Kategorien zuordnen können.
Mit dem Einsatz von Open Source Modellen kann KI heute leicht in Anwendungen integriert werden und die Effizienz bei der Bearbeitung von Kundenanliegen steigern.
targenio ist für Versicherungsunternehmen, auch VU-Template genannt, speziell auf die Anforderungen und Arbeitsweisen von Versicherern konzipiert, die Reklamationen und Beschwerden bearbeiten.
Es gibt einen großen Unterschied zum Workflow-Ansatz zur Bearbeitung von Kundenanliegen. Der Schwerpunkt des VU-Templates liegt auf der sorgfältigen Dokumentation eines Vorgangs, um Compliance-Anforderungen zu erfüllen und Daten für Auswertungen zur Verfügung zu stellen. Die eigentliche Bearbeitung findet, wie bei Versicherungsunternehmen üblich, direkt in den Bestandssystemen statt. targenio wird hier vorrangig zur Protokollierung einer ordnungsgemäßen Bearbeitung eingesetzt.
Auch wenn das konkrete Ausführen von Tätigkeiten in den zentralen Systemen des Versicherers stattfindet, erlaubt das VU-Template die Planung und Dokumentation von einzelnen Aufgaben. Ebenso ist es möglich, Aufgaben an andere Mitarbeiter über targenio zu delegieren und die Erledigung der überwiesenen Aufgaben zu protokollieren.
Vorgang: Bei unserer targenio Lösung werden Aktivitäten, wie die Kategorisierung des Kundenanliegens, oder die Erfassung einer Lösung, auf Vorgangsebene konsolidiert. Damit trägt targenio dem Bedürfnis Rechnung, die Dokumentation eines Beschwerde-/Reklamationsvorgangs möglichst flexibel und einfach durchführen zu können.
Spezifische Felder: Das VU-Template sieht bereits typische Felder und Daten vor, die bei einem Versicherungsunternehmen bei der Bearbeitung von Kundenanliegen erfasst werden müssen. Zum Beispiel gibt es Vertragsdaten und Vermittlerdaten oder Felder zum Protokollieren von Ombudsmann-Entscheidungen.
Bearbeitungsschritte: Der Anwender kann in beliebiger Reihenfolge die notwendigen Bearbeitungsschritte in targenio planen und erfassen. Diese Aufgaben kann er mit einem Termin versehen und an einzelne Mitarbeiter zur Bearbeitung übergeben. Das Erledigen dieser Aufgaben protokolliert targenio ebenfalls.
Vorgang bleibt offen: Bis zum Erledigen des Vorgangs können alle Informationen, inklusive der Kategorisierung und der erfassten Lösungen, jederzeit geändert werden. Die Bearbeiter haben damit die vollständige Flexibilität für eine angemessene Dokumentation der Beschwerde- und Reklamationsbearbeitung.
Takeaway
Das targenio VU-Template unterstützt optimal die Anforderungen von Versicherungsunternehmen an eine Reklamations- und Beschwerdelösung.
Das VU-Template ist flexibel und einfach zu bedienen.
Mit dem targenio VU-Template erfüllen Versicherer alle Anforderungen der BaFin hinsichtlich Dokumentation und Auswertungen zu Beschwerden und Reklamationen der Versicherten.
https://targenio.de/wp-content/uploads/2024/03/targenio-VUTemplate-Symbolfoto.jpg427640Michael Kolbenschlaghttps://targenio.de/wp-content/uploads/2024/02/targenio-logo.svgMichael Kolbenschlag2021-02-24 13:39:222024-03-14 09:42:28targenio für Versicherer
Beim Designen von Prozessen muss nicht nur der Inhalt der Aufgabe und der Aufgabenträger bestimmt werden. Es muss auch der Termin bestimmt werden, bis zu dem die Aufgabe erledigt werden soll. Die Notwendigkeit, Aufgaben und Prozesse mit Terminen zu versehen, kann aus unterschiedlichen Gründen bestehen:
Gesetz: Es sind gesetzliche oder regulatorische Vorgaben einzuhalten. So sehen etwa die europäischen Fluggastrecht vor, dass Passagiere innerhalb von sieben Tagen die Kosten für ihr Flugticket erstattet werden muss, sollte die Verbindung von der Fluggesellschaft storniert werden.
Prozesse: Wertschöpfungsketten und interbetriebliche Abläufe kommen zum Stillstand, wenn Aufgaben nicht zu vereinbarten Terminen erledigt werden.
Kunde: Gegenüber Kunden gegebene Serviceversprechen („Sie erhalten Ersatzlieferung innerhalb von 24 Stunden“) können ansonsten nicht eingehalten werden.
Steuerung: Die Performance von Dienstleistern soll gemonitort werden. So erfolgt beispielsweise die Abrechnung von Leistungen externer Service- oder Call-Center auf Basis von Zeitvorgaben, die in Service Level Agreements geregelt sind.
Produktivität: Termine sind auch Ansporn für die Anwender und helfen ein hohes Produktivitätsniveau zu halten.
Verbesserung: Informationen zu Bearbeitungszeiten sind Grundlage für Prozessoptimierungen und helfen Verschwendung zu identifizieren.
Welche Bereiche sollen mit Terminen versehen werden?
Abhängig vom verfolgten Zweck und dem konkreten Einzelfall ist festzulegen, „was“ überhaupt mit einem Termin versehen und wie das Einhalten von Terminen bzw. Zeiträume gemessen werden sollen. Hierbei muss zunächst bestimmt werden, ob für
eine Aufgabe,
einen Teilprozess,
oder für den gesamten Vorgang
ein Termin definiert werden soll.
Vier Grundlinien für die Festlegung von Terminen
In unserer Praxis haben sich einige Grundlinien für die Festlegung von Terminen herausgebildet, die bezüglich dieser schwierigen Fragen eine erste Orientierung geben:
Soll mit einem Termin ein Serviceversprechen gegenüber den Kunden sichergestellt werden, dann ist es sinnvoll, einen Termin für den Abschluss des Gesamtprozesses zu definieren. Hier kann etwa festgelegt werden, dass mit Eingang des Anliegens im Kundenservice die Zeit zu laufen beginnt und sich danach der Termin für die abschließende Bearbeitung berechnet. Ein besonderes Augenmerk ist dabei darauf zu legen, dass der Abschluss der Bearbeitung aus Kundensicht bestimmt wird. Ansonsten besteht die Gefahr, dass Vorgänge vorschnell „zugemacht werden“, nur um den gesetzten Termin einzuhalten. Dieses Vorgehen provoziert in der Regel Folgekontakte, da das Anliegen aus Sicht den Kunden nicht zufriedenstellend gelöst worden ist.
Ist hingegen beim Bearbeiten eines Vorgangs immer eine bestimmte Organisationseinheit einzubeziehen (z.B. Einholen einer Stellungnahme bei Produktionsstätte A, B oder C), dann hat es sich bewährt, diese konkrete Aktivität (Stellungnahme abgeben durch Produktionsstätte) mit einem Termin zu versehen. So kann sichergestellt werden, dass die Bearbeitung nicht ins Stocken gerät, weil die Rückmeldung aus Produktion nicht vorliegt.
Sind die Vorgänge sehr unterschiedlich und weicht die Bearbeitung der Einzelfälle sehr stark voneinander ab, dann empfiehlt es sich den Bearbeitungsworkflow zu abstrahieren und für jeden Abschnitt dieses Metaprozesses Termine festzulegen. Dieses Vorgehen ist insbesondere dann immer richtig, wenn unterschiedliche Organisationseinheiten an einem Vorgang arbeiten und die Verantwortung für die Bearbeitung wechselt.
Bei Prozessanalyse sollen Schwachstellen und Ineffizienzen identifiziert werden. Hier liegt der Schwerpunkt in Regel auf der Messung von Liege- und Bearbeitungszeiten, um hieraus Optimierungen ableiten zu können.
Termine bei (länderübergreifenden) Zusammenarbeit
Wenn das Festlegen von Terminen schon schwierig ist und gut überlegt werden muss, ergeben sich weitere komplizierte Fragen, wenn die Bearbeitung durch verschiedene Akteure erfolgt – insbesondere, wenn diese in verschiedenen Zeitzonen arbeiten.
Was passiert mit einem Termin, wenn ein Mitarbeiter in einem Service-Center an der amerikanischen Westküste feststellt, dass für die Bearbeitung zwingend die Stellungnahme eines Kollegen aus Deutschland erforderlich ist? Findet in diesem Fall eine Neuberechnung des ursprünglichen Termins statt oder erfolgt eine Berücksichtigung erst im Reporting? Diese und weitere Fragen können auch nur mit Blick auf den verfolgten Zweck beantwortet werden. Liegt der Fokus auf dem Einhalten eines Serviceversprechens gegenüber einem Kunden, dann wird die Zeitverschiebung keinen Einfluss auf den Termin haben – denn: dem Kunden ist es egal, ob die internen Abläufe eine Einbindung eines Kollegen aus einer anderen Zeitzone erfordert. Sollen mit der Terminsetzung schwerpunktmäßig die internen Abläufe koordiniert werden, dann ist eine Neuberechnung des Termins sinnvoll.
Reporting: in-time/out-of-time und Zeiträume
Das Einhalten von Terminen ist regelmäßig Bestandteil von Performance-Reports. Hier wird häufig angegeben, wie viele Vorgänge, Prozessabschnitte oder Aktivitäten den definierten Termin eingehalten haben oder nicht (in-time/out-of-time).
Diese binäre Betrachtung wird häufig erweitert, indem zum Beispiel in-time/out-of-time des Gesamtprozesses in Beziehung gesetzt wird zu in-time/out-of-time eines Prozessabschnitts. Auswertungen dieser Art haben ein hohes Konfliktpotential, da sie leicht finger-pointing ermöglicht („Ich konnte den Termin nicht halten, weil Du den Termin nicht gehalten hast“). Die hierbei zu lösende Herausforderung ist es, allen Beteiligten verständlich zu machen, dass bei ineinandergreifenden Aufgabenverteilungen jeder in der Verantwortung für das Einhalten der Termine ist.
Neben Reports zu in-time/out-of-time treten Reports über die Bearbeitungsdauer. Die Definition der auszuwertenden Messstrecken kann sehr komplex werden und bedarf der Beantwortung vieler Fragen, wie zum Beispiel:
Sollen Wochenenden / regionale Feiertage bei der Berechnung der Dauer berücksichtigt werden?
Erfolgt die Berechnung unter Berücksichtigung von definierten Kernarbeitszeiten oder rein kalendarisch? (Beispiel: Kunde schickt spätabends eine E-Mail. Ist der Startpunkt für die Messung der Eingang der E-Mail oder der Beginn der Regelarbeitszeit am nächsten Tag?)
Wie erfolgt die Berechnung, wenn die Art der Bearbeitung eines Vorgangs sehr stark von der modellierten Soll-Bearbeitung abweicht (Soll-Prozess sieht lediglich das Einholen einer Stellungnahme vor; im konkreten Vorgang mussten zwölf Stellungnahmen eingeholt werden)?
Wie wird mit „Langläufern“ umgegangen, die die Werte bei einer Durchschnittsbetrachtung erheblich beeinflussen? Langläufer können etwa entstehen, wenn für den Abschluss eines Vorgangs das Feedback des Kunden notwendig ist, der allerdings nicht reagiert.
Welche Auswertungscluster (0 bis 2h, >2h bis 6h etc.) sollen gebildet werden?
Auch diesen Fragen können nur unter Berücksichtigung der konkreten Auswertungsinteressen entschieden werden. Ihre Beantwortung sind Voraussetzung, damit der gesamte Komplex „Termine“ durch Software optimal unterstütz werden kann.
Takeaway
Aufgaben, Teilprozesse, Gesamtprozesse brauchen Termine, um eine ordnungsgemäße Bearbeitung sicherzustellen.
„Was“ mit einem Termin zu versehen ist, muss aus den übergeordneten Zwecken abgeleitet werden.
targenio ermöglicht eine effektive Steuerung über differenzierte Termine und erzeugt die Messpunkte, für durchdachte Auswertungen und Reports.
https://targenio.de/wp-content/uploads/2020/08/PXL_20240220_171423798-scaled.jpg14402560Michael Kolbenschlaghttps://targenio.de/wp-content/uploads/2024/02/targenio-logo.svgMichael Kolbenschlag2020-08-02 23:20:312024-03-27 14:01:37Termine, Termine, Termine
Die Bearbeitung von Kundenanfragen in einer globalen Supply Chain erfordert die zeitgleiche Zusammenarbeit von mehreren Fachleuten in den verschiedenen Vertriebs- und Logistikstufen. Das folgende Praxisbeispiel beschreibt einen Bearbeitungsablauf mit parallelen Teilprozessen.
Wie targenio die Vorgänge zur kollaborativen Bearbeitung bereitstellt
Ein Kunde spricht seinen Vertriebsmitarbeiter in einer Vertriebsniederlassung mit der dringenden Bitte zur Beschleunigung seiner Lieferung an. Der Vertriebsmitarbeiter startet in seinem Auftragssystem einen targenio Vorgang zur Klärung eines neuen Liefertermins. Ein Teilprozess für die Eingangsprüfung in targenio startet mit Klick auf einen Button im Auftragssystem. Dabei öffnet sich ein Dialog, der die relevanten Daten zum Auftrag anzeigt und mit Eingaben zum Wunschtermin und dem Grund der Anfrage angereichert wird. Im nächsten Schritt plausibilisiert das System die erfassten Daten automatisch und prüft sie auf Vollständigkeit. Beispielsweise prüft es, ob zu dem Auftrag bereits ein Vorgang erfasst wurde, oder ob dieser Mitarbeiter aus dem Vertrieb für diesen Kunden eine Beschleunigung des Liefertermins initiieren darf. Bei erfolgreichem Durchlaufen der Eingangsprüfung ermittelt targenio regelbasiert den verantwortlichen Supply Chain Agent (SCA). Anschließend startet es jeweils für den Mitarbeiter im Vertrieb und den SCA einen Teilprozess zur Bearbeitung dieser Kundenanfrage.
Der Supply Chain Agent (SCA) übernimmt
Der SCA prüft anhand einer Checklisten-Funktion den Vorgang und entscheidet damit über die weitere Bearbeitung. Für die Beschleunigung einer Lieferung kann je nach Sachlage die Einbindung verschiedener Fachabteilungen erforderlich sein. Zum Beispiel kann er das Lieferantenmanagement für die Beschaffung von noch ausstehenden Lieferungen, den Wareneingang für eine priorisierte Wareneingangsprüfung, die Montage/Fertigung, das Qualitätsmanagement, die Verpackung, den Zoll und/oder das Versandlager anfragen.
Über das Collaboration-Cockpit wählt der SCA die einzubindenden Ansprechpartner der Fachabteilungen aus. Er informiert diese und startet deren Teilprozess zur Bearbeitung der Anfrage. Zusätzlich setzt der SCA sein Wiedervorlagedatum. Mit dem Collaboration-Cockpit behält der SCA jederzeit einen detaillierten Überblick zum Bearbeitungsfortschritt der Kundenanfrage.
Die eingebunden Fachabteilungen erhalten automatisiert eine E-Mail mit einem Link auf ihren Teilprozess. Die Fachleute prüfen und bearbeiten anhand der für sie hinterlegten Checklisten die Anfrage zur Lieferpriorisierung. Bei Bedarf können diese selbst weitere Fachleute über ihr Collaboration-Cockpit in die Bearbeitung einbeziehen. Im Grundsatz verläuft die Bearbeitung in den Teilprozessen autark, jedoch beeinflussen sich die Prüf- und Bearbeitungsergebnisse der verschiedenen Teilprozesse wechselseitig. Die Recherche- und Bearbeitungsergebnisse in den Teilprozessen lösen „Ereignisse“ aus, die den Bearbeitern in den anderen Teilprozessen angezeigt werden. Da verschiedene Ereignisse zeitgleich auftreten können, und unterschiedliche Relevanz für die Bearbeitung eines Vorgangs haben, sind die Ereignisse logisch geordnet. Das wichtigste Ereignis bestimmt den Status eines Teilprozesses und bildet damit die Basis für eine priorisierte Bearbeitung.
So sind alle Bearbeiter über die verschiedenen Teilprozesse hinweg stets informiert. So können sie über ihre weitere Bearbeitung mit den aktuellsten Informationen entscheiden. Anhand der Bearbeitungsergebnisse der Fachabteilungen entscheidet der SCA, ob er weitere Experten einschalten muss. Oder ob er dem Mitarbeiter im Vertrieb eine verbindliche Rückmeldung für seinen Kunden geben kann.
Takeaway
Der Nutzen der kollaborativen Bearbeitung mit parallelen Bearbeitungsprozessen für die Prozessteuerung liegt in der massiven Reduktion der Komplexität in den Workflows und erleichtert die Automatisierung und Auswertung.
Zudem können die Agents Veränderungen und Anpassungen an den Workflows schneller und einfacher umsetzen, da nur betroffene Teilprozesse und nicht ein komplexer Workflow geändert werden.
Im Tagesgeschäft erfolgt die Bearbeitung schneller durch die Parallelisierung von Aufgaben, anstatt einer sequentiellen Bearbeitung.
Zusätzlich reduzieren sich die Bearbeitungsaufwände, da die Arbeitsergebnisse aus anderen Teilprozessen nutzbar sind.
Für die Anwender verbessert sich die Usability erheblich, weil sie nur die Aufgaben im Teilprozess sehen, die sie konkret bearbeiten und nicht alle anderen Aufgaben, so wie das bei komplexen linearen Workflows der Fall ist.
https://targenio.de/wp-content/uploads/2024/03/parallele-Prozesse.png7611831Michael Kolbenschlaghttps://targenio.de/wp-content/uploads/2024/02/targenio-logo.svgMichael Kolbenschlag2020-07-20 23:23:052024-04-08 08:56:06Vorgänge kollaborativ und parallel bearbeiten
Deutschland ist eine der führenden Exportnationen und die Internationalisierung ist einer der zentralen Erfolgsfaktoren für die deutsche Wirtschaft. Wikipedia benennt die unternehmerischen Vorteile wie folgt:
„Internationalisierung heißt die geografische Dezentralisierung der Unternehmenstätigkeit auf internationalen Märkten. Motive für Internationalisierung sind die Sicherung des Absatzes durch größere Marktnähe, die Senkung der Lohn- und Lohnnebenkosten, Umgehen von Importrestriktionen, Realisierung von Transportkostenvorteilen, Investitionsfördermaßnahmen durch die ausländischen Staaten sowie Unabhängigkeit von der Entwicklung der Devisenkurse.“
Die unternehmerischen Vorteile der dezentralen Organisation sind realisiert, wenn ein System die Abläufe in den Geschäftsprozessen länderübergreifend abbildet und automatisiert. Typische Komplexitätstreiber sind beispielsweise Unterschiede in der lokalen Aufbauorganisation, länderspezifische Regulatorien oder heterogene IT- und Datenversorgung.
Use Case multicountry Vorgangsbearbeitung
Daraus entsteht eine typische Aufgabenstellung für die länderübergreifende Automatisierung von Geschäftsvorgängen, wie in diesem Use Case aus unserer Praxis:
Ein B2B Kunde aus Japan löst einen Geschäftsvorgang per API Schnittstelle aus seiner Anwendung im targenio System aus.
Der zentrale Kundenservice für die Asia Pacific Region in Malaysia übernimmt zunächst die Bearbeitung des Geschäftsvorgangs eines Kunden aus Japan.
Der Bearbeiter im APAC Kundenservice benötigt für eine Entscheidung zum Geschäftsvorgang eine Bewertung des Lagers für APAC die Region in Singapur.
Die Rückmeldung mit der Bewertung des APAC Lagers übersteigt die Wertgrenze, über die der Kundenservice in Malaysia entscheiden kann, und der Gesamtprozessverantwortliche in der Zentrale in Deutschland muss die Entscheidung freigeben.
Der Kunde, und die an der Bearbeitung beteiligten Anwender, erhalten mit der Freigabe automatisiert die Antwort.
Das ERP System verarbeitet automatisiert und verbucht die Lösung des Geschäftsvorgangs.
An der Bearbeitung dieses Vorgangs sind Anwender in vier unterschiedlichen Ländern, in unterschiedlichen Zeitzonen und mit unterschiedlichen Sprachen beteiligt. Der Kunde und die Bearbeiter des Geschäftsvorgangs erfassen und sehen die Daten zum Vorgang in ihrer Landessprache, in ihrer Landeswährung und Termine werden für ihre Zeitzone ermittelt.
multicountry Anforderungen an Business Software
Für die automatisierte Bearbeitung von multicountry Geschäftsvorgängen ermöglicht targenio
die Anzeige der Bedienoberfläche und der Katalogwerte in verschiedenen Sprachen,
im Kontaktmanagement die Verwendung von Vorlagen und Textbausteinen in den Kommunikationssprachen der Kunden,
die Umrechnung und Anzeige von Beträgen in der Konzern- und Landeswährung und
die Ermittlung und Anzeige von Terminen für die Zeitzone des Anwenders.
Die Screenshots zeigen die Sicht auf die gleichen Geschäftsvorgänge, die in unterschiedlichen Sprachen angezeigt und bearbeitet werden können:
Herausforderungen bei Implementierung von Lösungen
targenio ist von Grund auf für multicountry Geschäftsvorgänge ausgelegt. Nach unserer Erfahrung erfordern drei Aufgaben bei der Implementierung besonderes Augenmerk:
targenio übersetzt Begriffe in Masken und Meldungen werden gemäß den im Konzern üblichen Begriffen einheitlich und hinterlegt diese. Einer Funktion im targenio Customizer exportiert alle Begriffe in eine Excel Tabelle, die sie nach Bedarf sortiert und übersetzt. Im Anschluss importiert targenio die übersetzten Begriffe wieder ins System, die sich danach unmittelbar testen lassen.
Bei der Aggregation von mehrsprachigen Daten in der Aufgabenliste oder im Reporting entstehen durch das Verdichten von Daten aus mehreren Businessobjekten, zum Beispiel Kontakt, Vorgang, Aufgabe, und den verschiedenen Sprachen große Datenmengen, die targenio dem Anwender sehr schnell anzeigt und bereitstellt. Die Performanceoptimierung dieser Funktionen ist, während der Implementierung, eine kontinuierliche Aufgabe.
Neben der Anpassung der Oberfläche, berücksichtigt targenio auch länderspezifische Anforderungen als Varianten im Prozess, beispielsweise erfordert jede Weblösung in China die Anzeige der ICP Lizenz oder in den Ländern sind verschiedene Zahlungsmethoden üblich (Scheck statt Überweisung). Der Behandlung von länderspezifischen Anforderungen in den Workflows wollen wir einen eigenen Blog Beitrag widmen.
multicountry Geschäftsvorgänge erfolgreich ausrollen und betreiben
Die Automatisierung von multicountry Geschäftsvorgängen geht über die technische Umsetzung hinaus. In weitere Blogbeiträgen befassen wir uns mit Themen, wie dem Abbilden von länderspezifischen Abläufen und Anforderungen, mit Rolloutstrategien, der Sicherstellung von Stabilität und Performance in einer globalen IT-Infrastruktur sowie dem Access- / Usermanagement.
Takeaway
Die dezentrale internationale Organisation ist ein zentraler Erfolgsfaktor für Unternehmen.
Geschäftsvorgänge können länderübergreifend automatisiert werden.
targenio ermöglicht die übergreifende Bearbeitung mit Sprachen, Währungen und Zeitzonen.
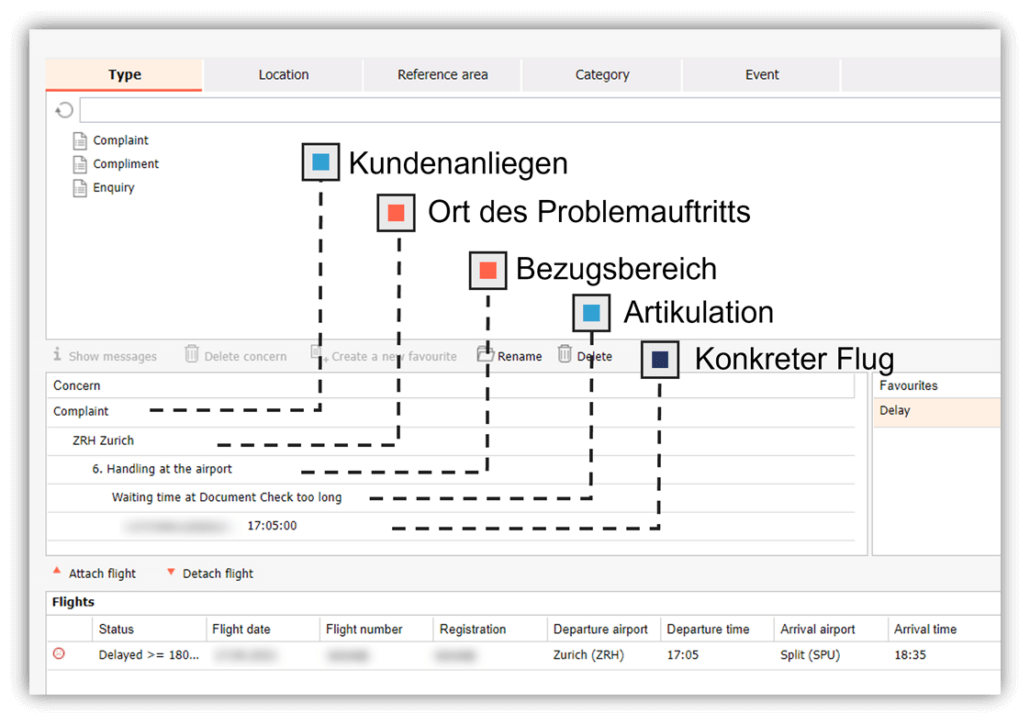
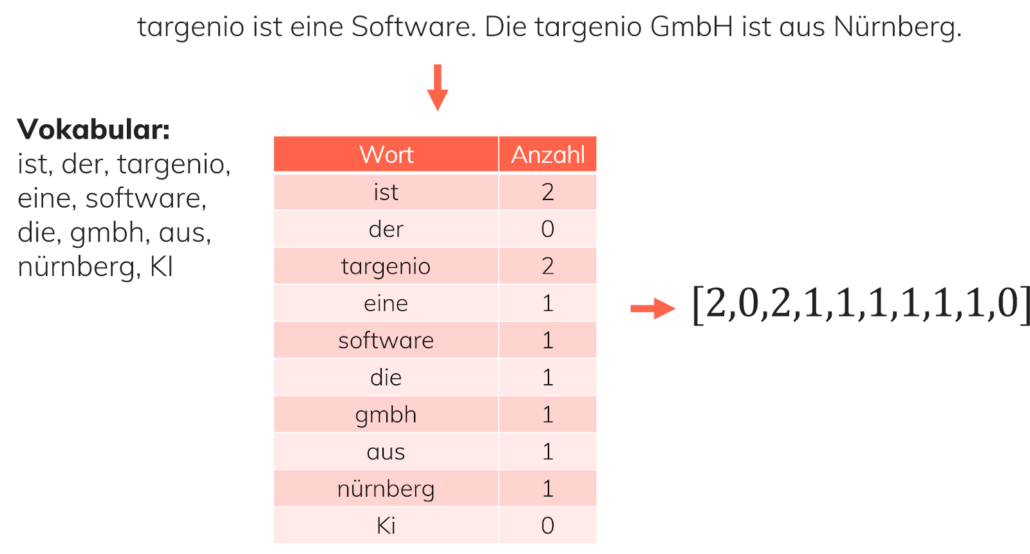
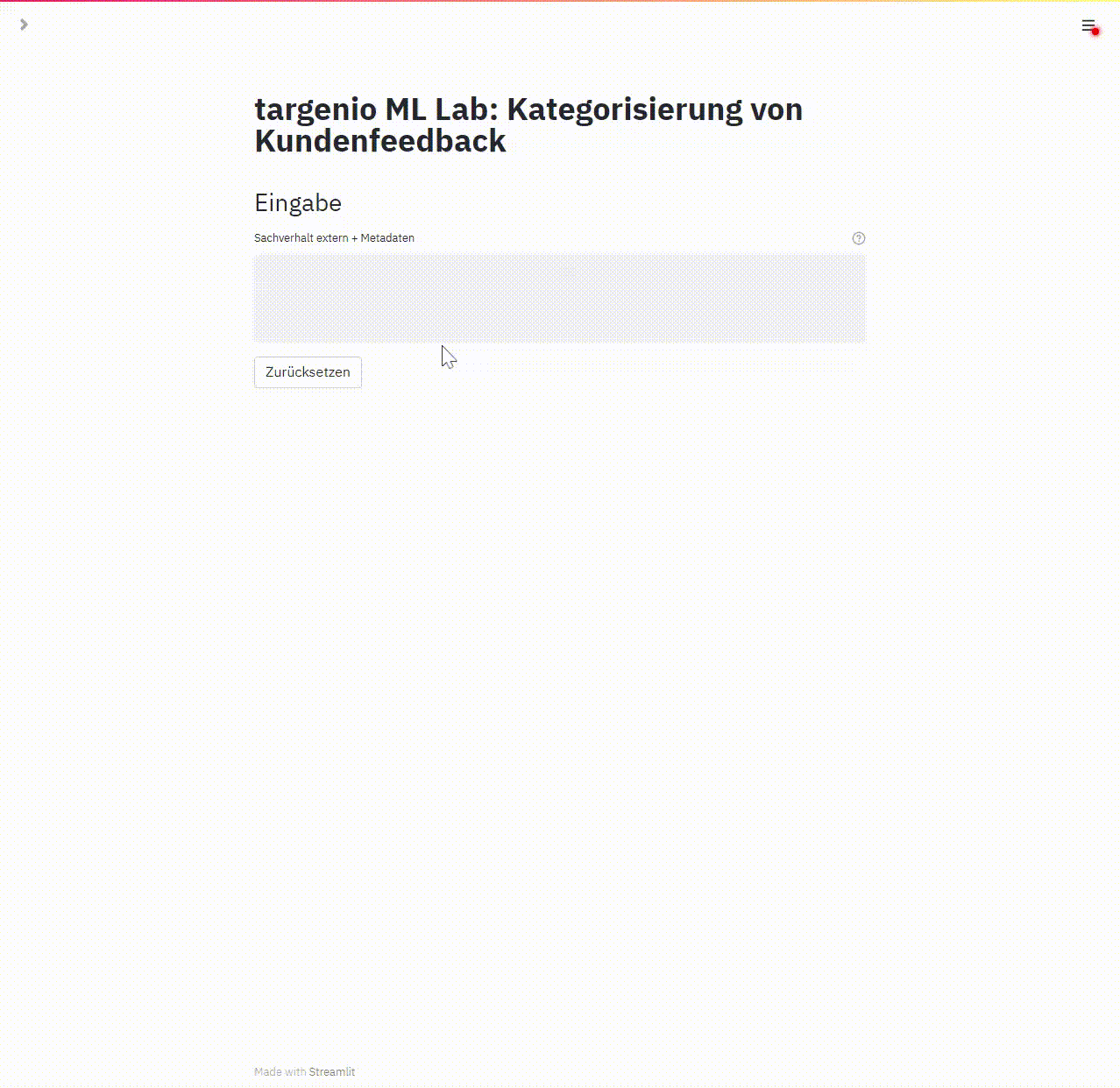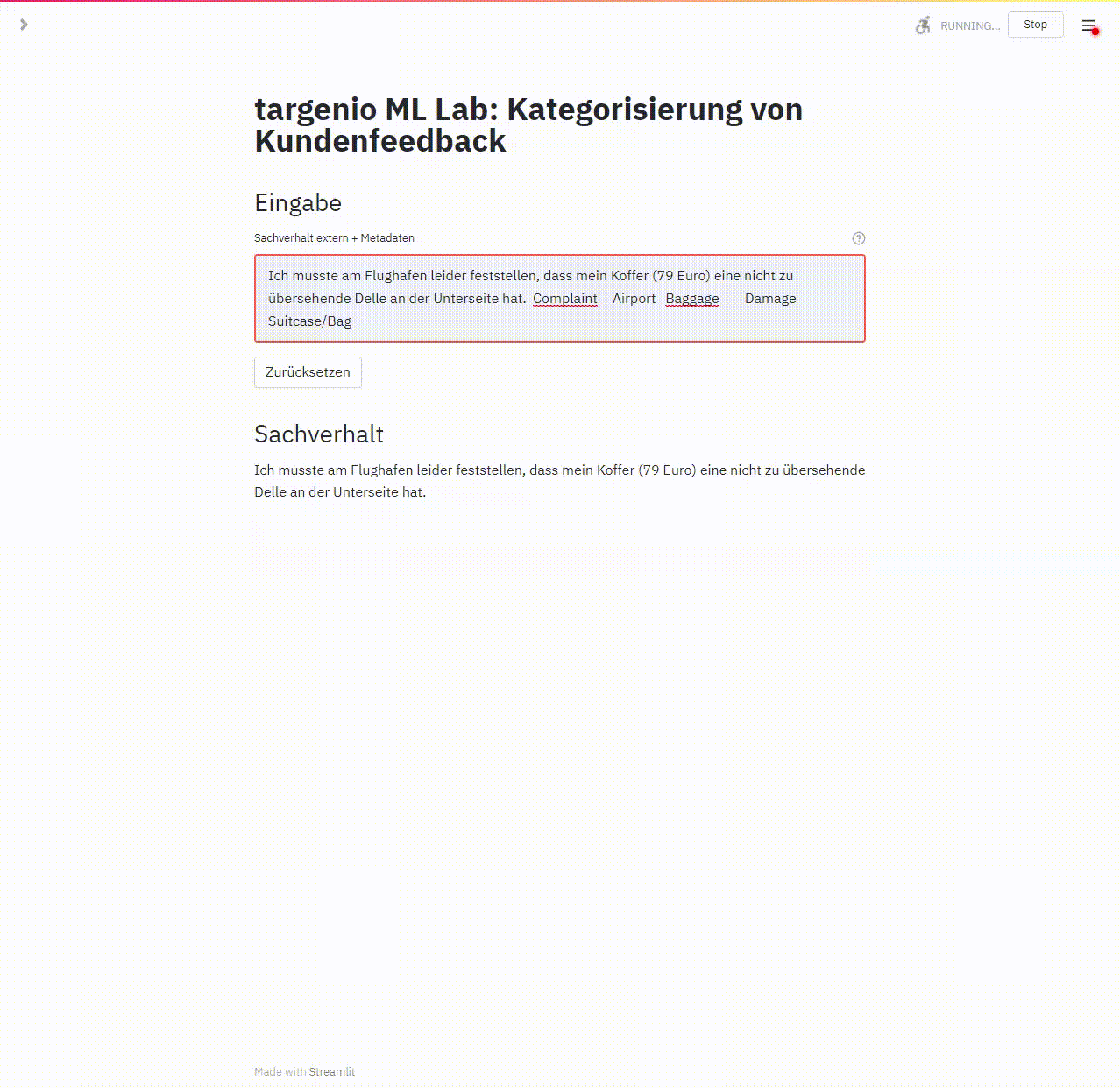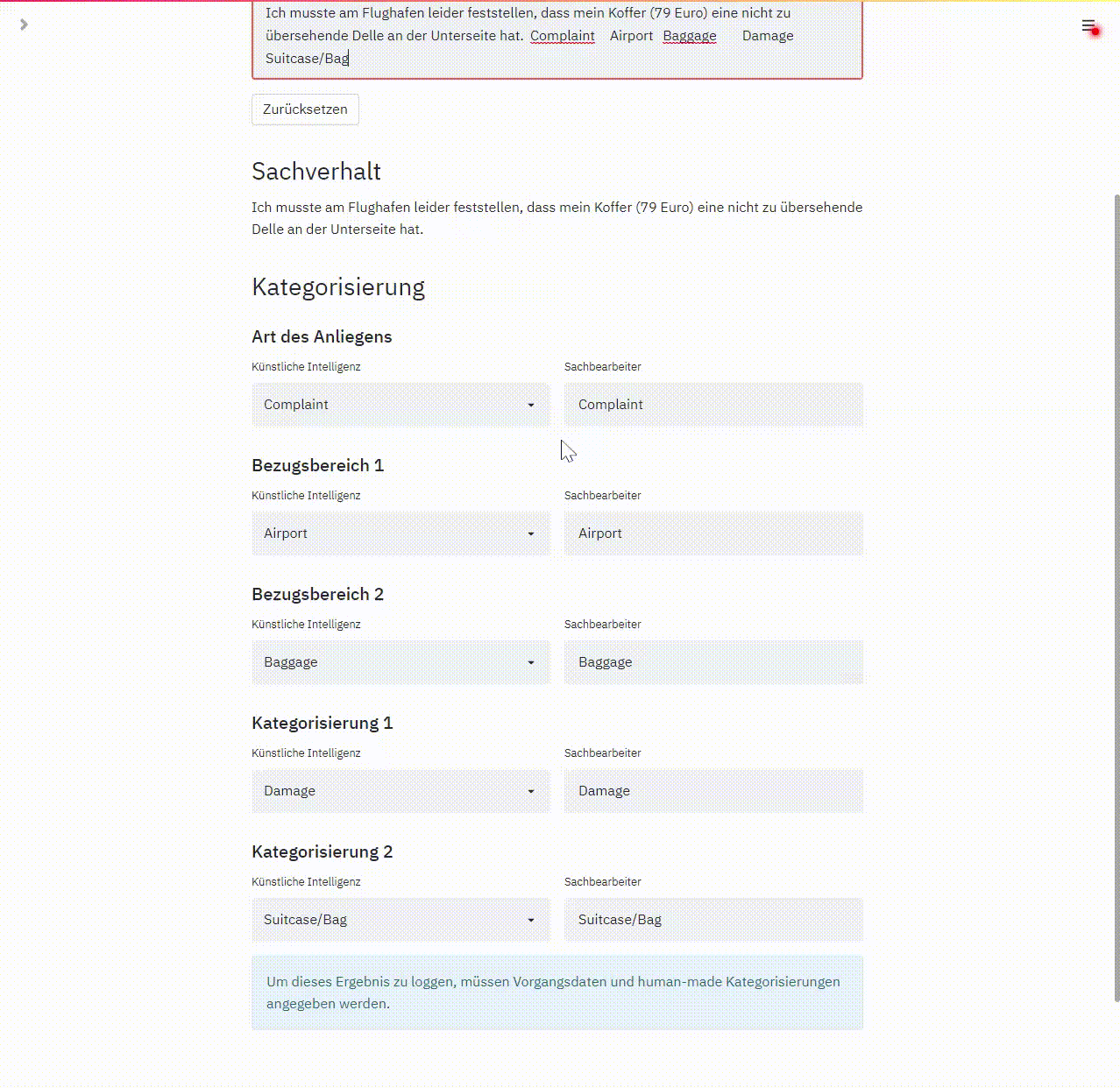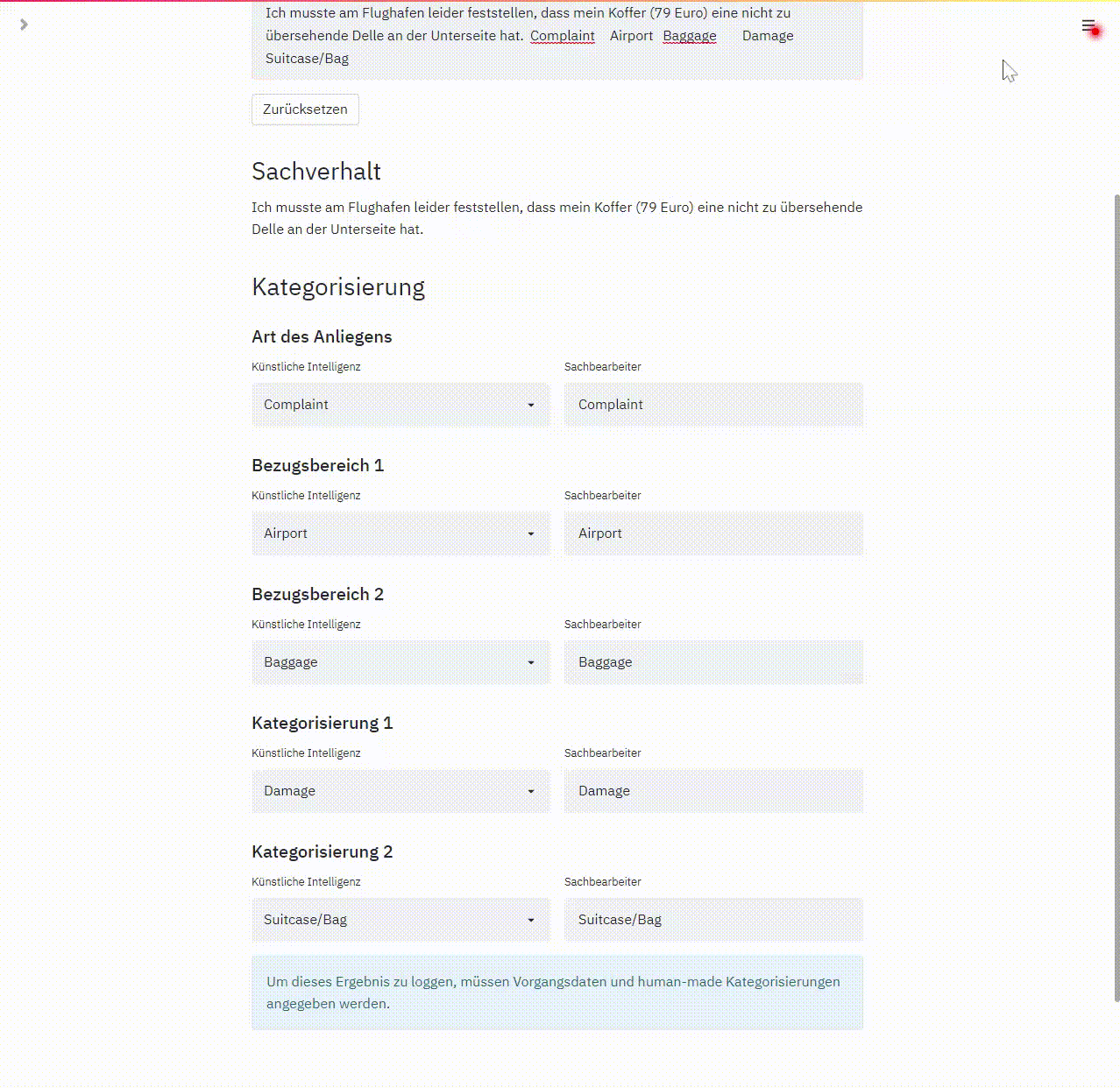
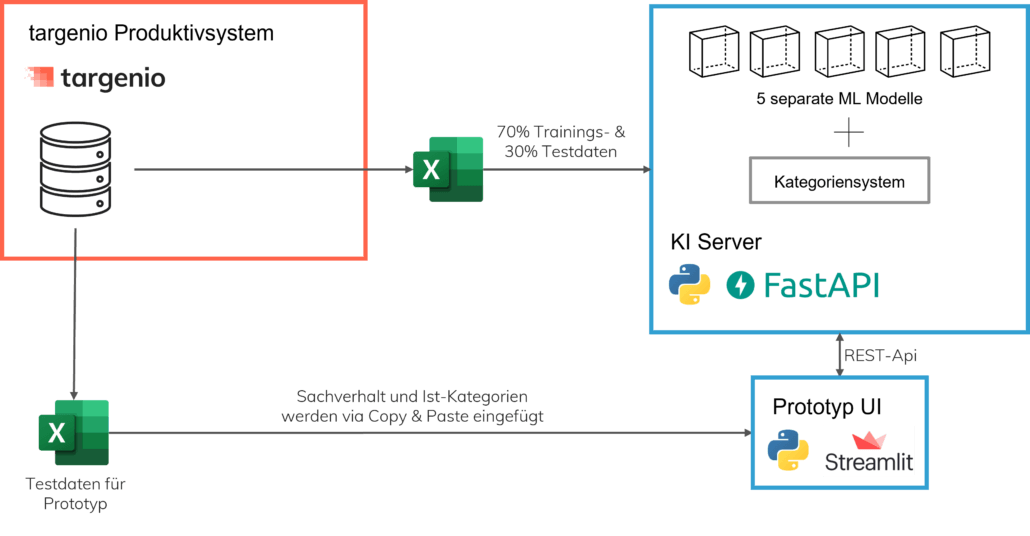
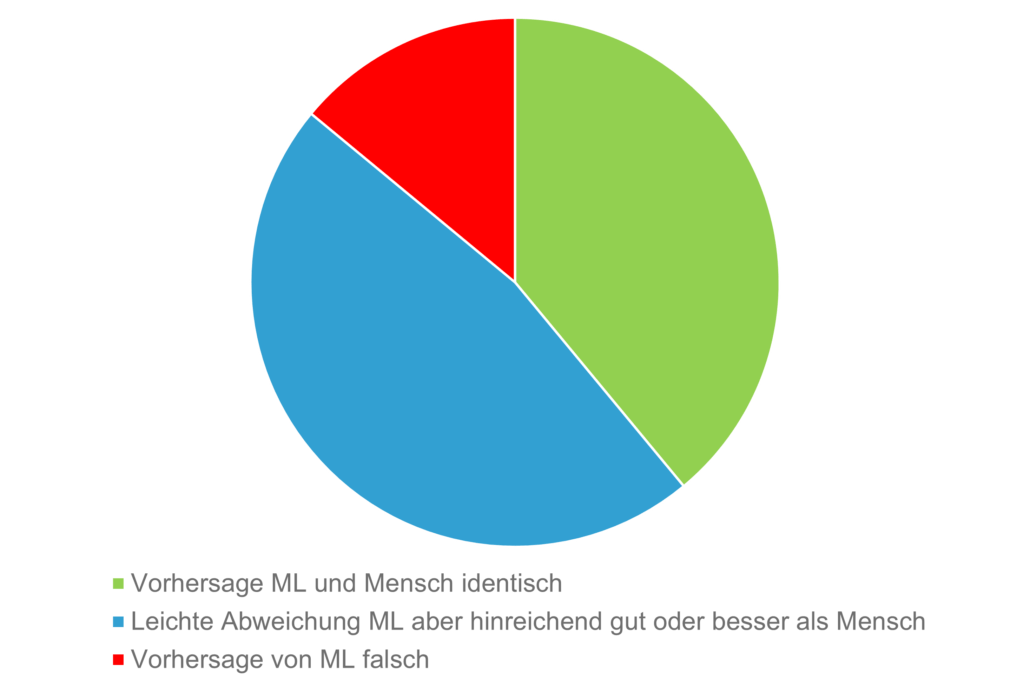
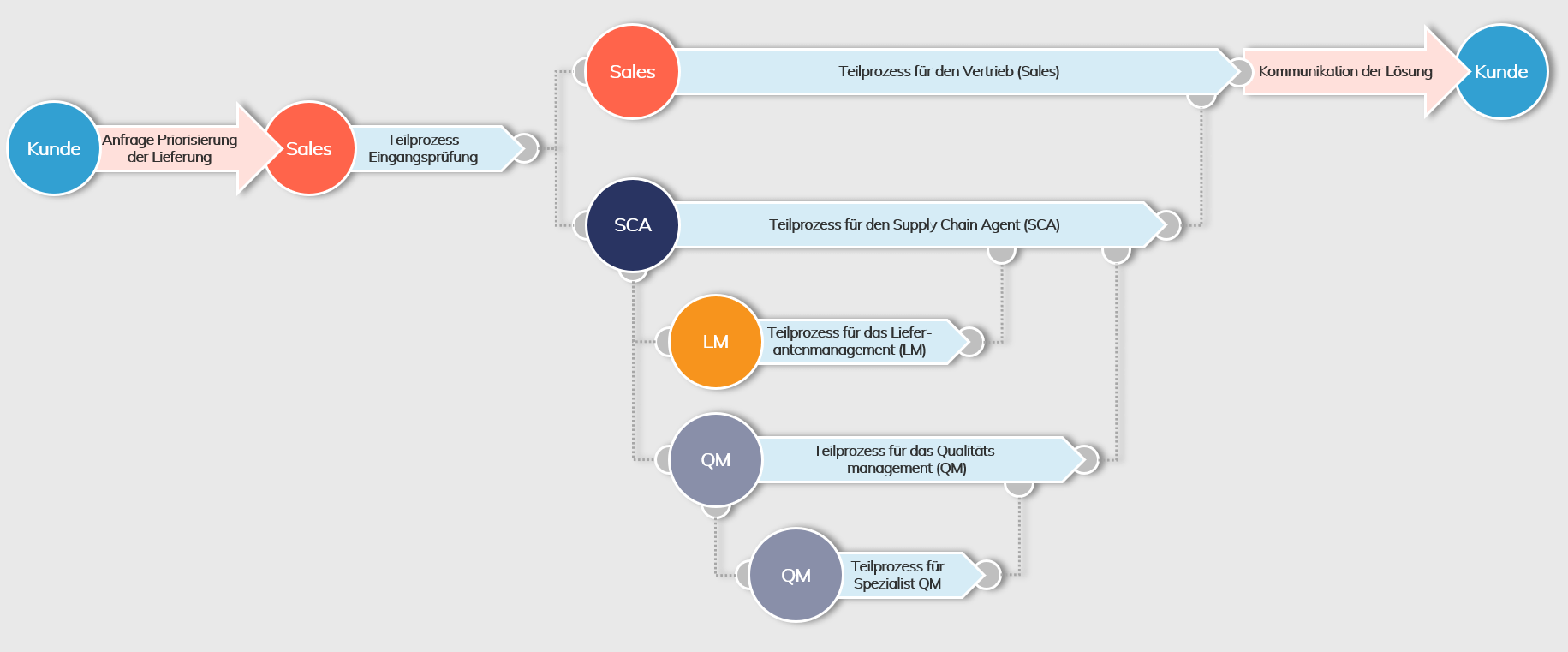
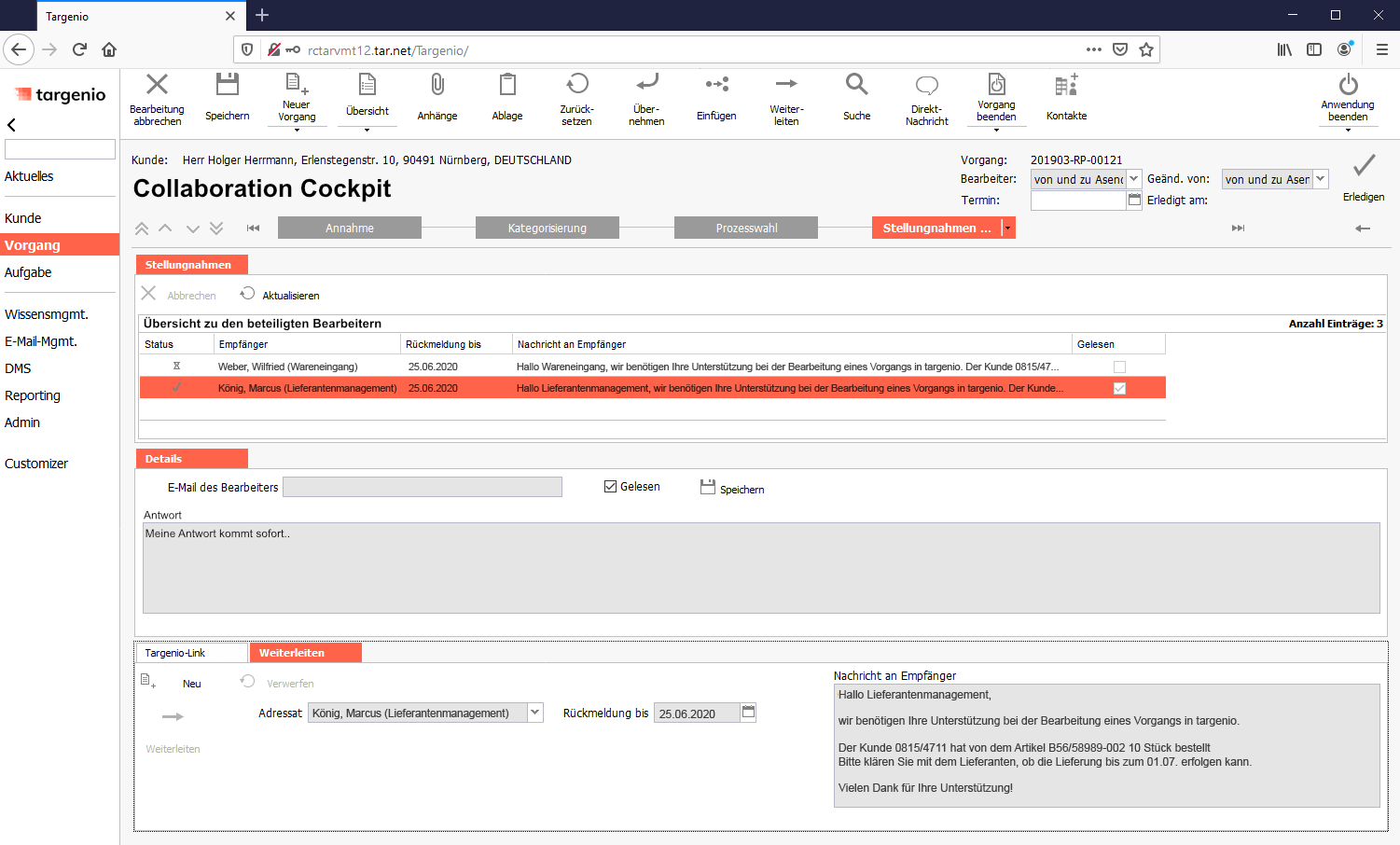
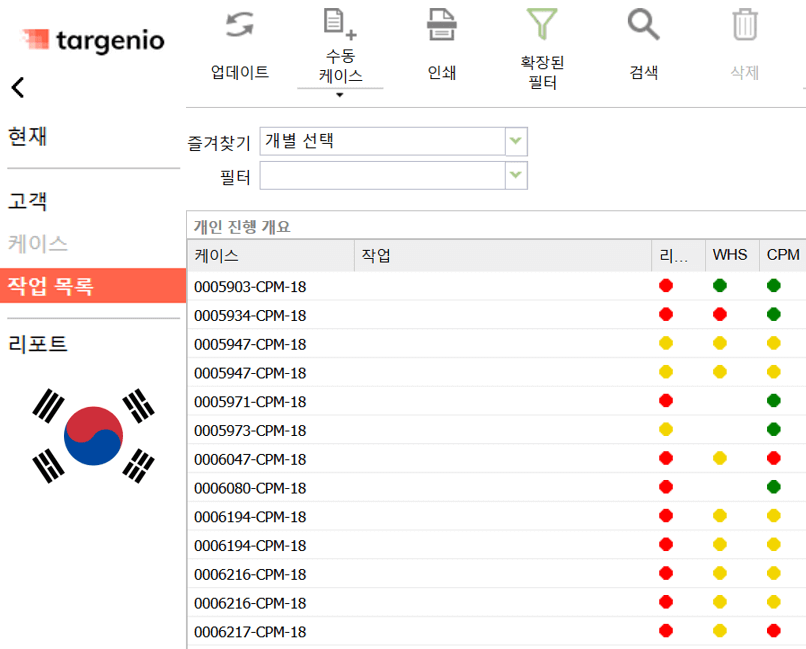
 targenio
targenio targenio
targenio targenio
targenio Condor
Condor